Hina Bashir, Kanwal Majeed, Sumaira Zafar, Ghulam Zohra, Syed Farooq Ali*, and Aadil Zia Khan
School of Systems and Technology, University of Management and Technology, Lahore, Pakistan
* Corresponding Author: [email protected]
ABSTRACT Over the last couple of decades, human fall detection has gained considerable popularity, especially for the elderly. Elderly people need more attention as compared to others in their homes, hospitals, and care centers. Various solutions have been proposed to deal with this problem, yet, many aspects of this problem are still unresolved. The current study proposed an approach for human fall detection based on the Visual Geometry Architecture of deep learning. The presented approach was weighed up with state-of-the-art approaches including ResNet-50 and even ResNet-101 by using MCF and URFD datasets, outperforming them with an accuracy of 98%. The proposed approach also outperformed these deep architectures in terms of performance efficiency.
INDEX TERMS Convolution Neural Network (CNN), deep learning, fall detection, ResNet-50, ResNet-101, VGG 16
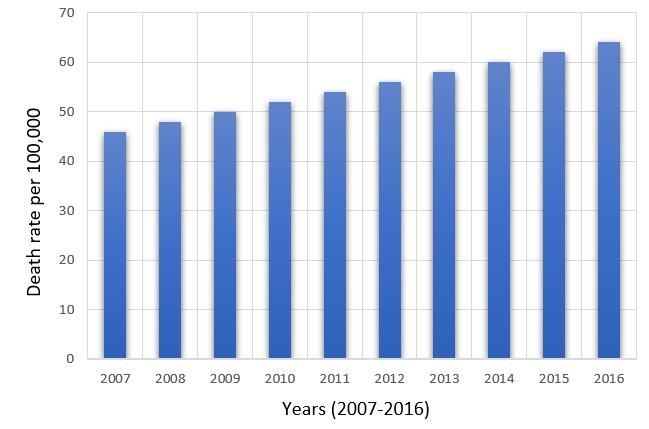
The elderly population is growing at a rapid pace all over the world. For instance, in China, the elderly people constitute about 10.1% of the total population and this figure is expected to rise to 35% by 2050 [1]. Similarly, in Tunisia, the elderly population is expected to increase to 17.7% of the total population by 2029 [2]. In Canada and Europe, most senior citizens prefer to stay at their homes [3]. Living alone is in itself a huge threat to the health and well-being of a person, irrespective of their age. In addition to that, the absence of caregivers also puts elderly people at a greater risk of injuries caused by accidents, especially falls. Every year in the USA, approximately one-third of its senior citizens, over the age of 65, suffer from fall-related injuries, resulting in an annual cost of around $31 billion [4]. The statistics of the total number of falls in the US starting from the year (2007-2016) is shown in Figure I [5]. In the UK, 70% of the deaths among elderly people, 75 years and above, are due to falls [6]. In recent years, with the advent of high-tech smart homes, new applications are being developed to improve the quality of life for the old and vulnerable group of people. One such active area of research is automatic fall detection.
The economic impact of fall-related injuries, especially in elderly population, is substantial. Recent research [7] shows that in 2010, the total per capita cost of fall-related injuries in the USA was 1,186 USD for people over the age of 75. This was much higher than the per capita costs of people belonging to other age groups. For instance, for people younger than 35, the costs were less than 300 USD. From another report [8], it can be seen that the total number of people injured due to falls is much higher in the elderly population. In the 75+ age group, the total number of cases was 456,000. If we compare this with
the younger demographic groups, for instance, the 35-44 year age group, the cases come down to 303,000. Figure I shows the statistics of fall-related injuries corresponding to various states of the US.
FIGURE1. Distribution of Fall Death Rates Per 100,00 in the US Ranging from Year 2007-2016
It is important to mention that the impact of such injuries is greater in elderly people since they take much longer to recover as compared to younger patients [6]. Overall, these figures show the gravity of the problem. Fall detection becomes critical, particularly in situations when elderly people are alone, as it has been a growing trend in recent years. Fall detection technology can also help insurance companies to identify fraud cases. The slip and fall claims are the most common among staged accidents. This is because fall-related injuries are very hard to disprove and potential payouts can be very high [9]. The detection systems can help insurance companies to identify staged falls so that their money is spent only on deserving people. Timely recognition can facilitate the immediate delivery of medical care to the wounded.
According to the reports of World Health Organization (WHO), the number of surgeries and death rates from fall incidences are among the major health issues in the whole world [6]. According to it, falls cause 37.3 million critical injuries and 646,000 deaths each year, leading to significant health and financial issues worldwide. 25
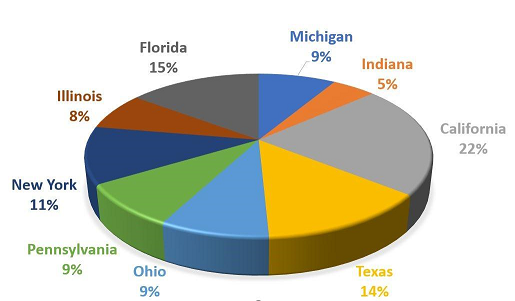
FIGURE 2. Statistics Showing Fall Injuries Corresponding to Various States of the US
The cost of fall-related injuries varies by different age brackets. According to a study in the US on emergency departments
of hospitals [7], the per-person cost due to fall-related injuries, in (18-24) age bracket was 238.24$. While, for elderly people of age 75 and above, it was much higher, around 1186.00$. This clearly shows a huge difference in cost due to fall injuries between the young and the elderly. The current study proposed a deep-learning algorithm to solve the problem of human fall-detection. It also compared the proposed approach with the state of the art existing deep architectures in terms of the accuracy. Moreover, this comparison has also been made in terms of performance efficiency as well.
The remaining research is sorted-out as follows: Section II describes the related work, while Section III explains the proposed methodology and data set. Section IV presents various experiments along with their analysis, while the conclusion and future work is given in Section V.
In 2015, Saiymon et al. developed a flexible robot that relied on an edge detection-based system to perceive human fall [10]. Microsoft kinetic and PC sensors were used to assist people with their movements. This procedure, removed the limitations associated with systems that relied on a fixed sensor to detect human falls. Chaccour et al. conducted extensive research on various systems, from fall detection to fall prevention, based on their sensor deployment [11]. Their main aim was to assist medical technologists in public health field regarding fall-related systems.
In 2020, Singh et al. reviewed different sensor technologies and their applications in human fall detection [12]. A comprehensive technological insight was provided into the existing fall detection system along with the classification of number of approaches, and then the challenges which were encountered during the implementation. They classified the fall detectors into three categories, namely ambiance-based, wearable, and hybrid sensing detectors, which were then further explored by the sensor technology. A comprehensive overview was provided by competing for sensor technology which ranged from an accelerometer, radar to camera-based and pressure sensor, suffuse into a fall-detection system.
In the same year, Ruzaij et al. proposed a wearable low-cost fall detection and alarm system that was used to reduce false positive alarms [13]. It was used to monitor the movement of human beings and in case of any fall, the system sends a caution message to the relevant authority.
In 2006, Miaou et al. proposed a fall detection system by using MapCam (Omni camera) [14]. They combined personal information with parameters, such as height and weight and achieved a classification accuracy of 79.8%. Without adding personal parameters, the accuracy came down to 68%.
Doukas et al. proposed a feature-based human fall detection framework that depends on the sound, video, and motion captured from the patient's body [15]. Audio and video were used to detect features, such as frequency, acceleration, speed, and closeness impact. Tracking techniques were applied to a sequence of frames, while audio data processing and sound directionality, together with visual location and motion information of the subject can detect the fall. The post-fall analysis including the motion behavior of subject was used to compute the severity of the fall.
In 2013, Ali et al. proposed a feature-based approach for human fall detection [16]. The approach used various geometric, location, and motion-based features including centroid, head position, aspect ratio, fall angle, motion vector, and aspect ratio and achieved an accuracy of 96.58% on the MCF dataset. They extended the problem and proposed a fast and more accurate real-time system under a boosting framework [17]. In their approach, novel temporal and spatial variance based features were proposed which comprised of geometric orientation, discriminatory motion, and the location of the person. Their proposed approach achieved an accuracy of 99% on the Multiple Camera Fall data set.
In 2016, Wang et al. proposed an approach for human fall detection, based on the PCANet model [18]. The approach not only predicted frames, however, also the video sequence. They classified the frames into three labels namely, standing, falling, and fall. Two linear SVM models were trained, one for the detection of a single frame, and the other model was trained for the detection of a video sequence. The features extracted from PCANet were fed to linear SVMs. The approach obtained sensitivity and the specificity of 93.81% and 98.4%, respectively on the MCF dataset.
In 2018, Min et al. proposed an approach for human fall-detection, based on scene analysis [19]. The scene analysis was performed by Region-based convolutional neural networks (R-CNN) to compute the space relationship between human beings and furniture. The handcrafted features including centroid, aspect ratio, and motion history of the human beings were detected and tracked. By using the space relationship and handcrafted features, the fall on furniture was effectively detected. The method not only detected fall on furniture, such as chairs and sofas, however, it also distinguished them from other alike activities.
Shoja et al. described a model for human fall detection by using Recurrent Neural Network (RNN) [20]. Every time a fall was observed in the video, an alarm was generated and a message was immediately sent to the medical staff. RNN was not very well trained due to the ’vanishing gradient’. To overcome this issue, Long Short-Term Memory (LSRM) was used. In 2019, Espinosa et al. [21] presented a multi-camera vision-based fall detection system. They took advantage of CNN’s visual feature extraction by using the optical flow method. In the same year, Santos et al. considered an IoT and the Fog Computing environment for human fall detection [6]. They proposed a CNN which was composed of three convolutional layers, two max pools, and three fully connected layers, as their deep learning model. Accuracy, sensitivity, specificity, precision, and the Matthews Correlation Coefficient were used to evaluate the performance, however, much better results were attained while using data augmentation during training process.
In 2020, Han et al. proposed the two-stream approach for fall detection by constructing a lightweight network model by replacing a convolutional neural network with a simplified one [22]. MobileVGG was put-up as a lightweight network model to replace the conventional convolution with disentangled and efficient combinations of point convolution and depth convolution. Cameron et al. applied the multistream learning model based on a CNN to provide a solution for the two categories of human fall detection problem [23]. They used high-level handwrought features as input, to cope with this situation. Their approach consisted of extracting high-level handcrafted features, for instance, human pose estimation and an optical flow and using each one of them as an input for a perceptible VGG16 classifier. Besides, these experiments showcase which features can be used in fall detection. The results showed that by gathering the govern input learners, the approach surpassed in terms of sensitivity rates and accuracy.
Visual Geometry Group (VGG-16), a deep network having 3 fully connected and 13 convolutional layers, is specially designed for image classification [24]. VGG-16 proposed the idea of an effectual receptive field and gave idea of simple and homogenous topology. However, it also used the computationally expensive fully connected layers. As a result, they required more computational power and memory [25].
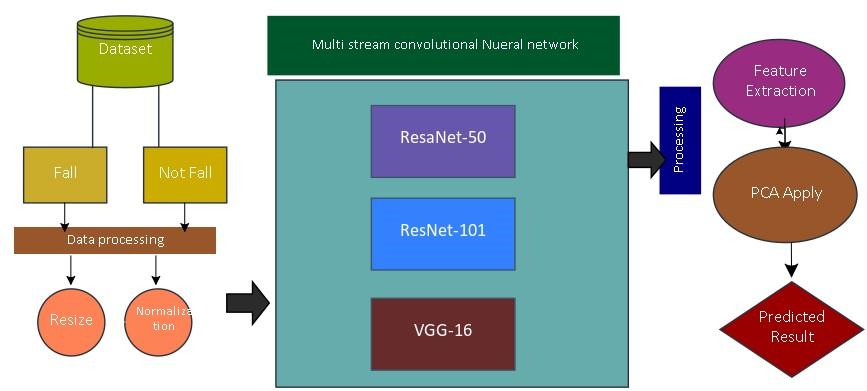
FIGURE 3. Methodology
VGG-16 falls under the spatial exploitation category and uses a fixed size of input images, that is, 224×244. The spatial padding of the input of convolutional layer is preserved after every convolution, that is, 1-pixel padding is fixed for the convolutional layer of (3×3). Different deep architectures rely on different depths of convolutional layers. In VGG-16, the convolutional layers stack observed three fully connected layers, while total of 4096 channels were used in the first two layers. The third layer executes 1000-way for ILSVRC classification, therefore, each class holds 1000 channels. The final layer of the architecture is the SoftMax layer. The same configuration is used for all fully connected layers present in the network [26]. Equation 1-3. shows the output width, output height, and output matrix of VGG16. Moreover, it also proposed an idea of an effective receptive field and gave idea of simple homogeneous topology.
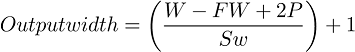
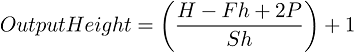
to calculate the pooling layer. The formula is given below;
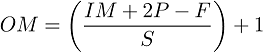
where,
The input fall videos were fragmented into frames then each frame observed further fall stages. Some data frames for fall videos are shown in Fig III [26].
SHOWING VARIOUS PARAMETERS OF VGG-16
|
Methods |
VGG-16 |
|
Top 5 errors |
7.4 |
|
input Size |
224*224 |
|
Number of convolution layer |
16 |
|
Filters Size |
3 |
|
Feature Maps |
3-512 |
|
Stride |
1 |
|
Weights used |
14.7M |
|
MACS used |
15.3G |
|
used FC layers |
3 |
|
Weights |
124 |
|
Number of MACS |
124M |
|
Total Weights |
138M |
|
Total MACS |
15.5G |
VGG-16 architecture has been shown in Fig III [3]. It shows different convolutional layers and how these layers interact with each other. The input of convolutional layer 1 consists of 224x224 RGB images that pass through various layers including stack, convolutional layer, and spatial pooling layer [27]. VGG-16 methods are shown in Table I [28].
Deep Residual Network (ResNet) seems to be an ANN developed to identify the issue of low accuracy while building a plain ANN with the deeper layers. In other words, Deep Residual Network’s objective is to make highly accurate ANN with deeper layers. The principle of a Deep Residual Network is to create ANN which can change the weight of a deeper layer [29].
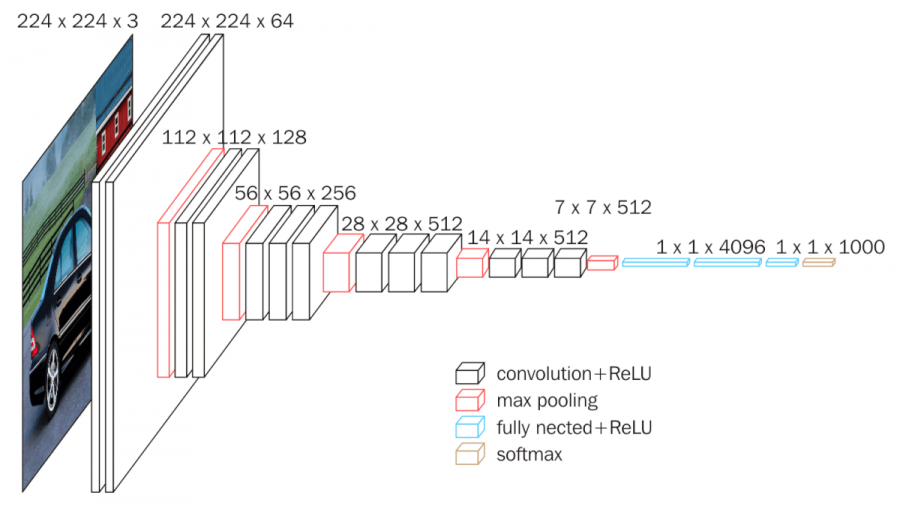
FIGURE 4. Architecture of VGG-16 [3]

FIGURE 5. Keyframes from MCF data showing human fall
Frames are extracted from different falls and no fall videos and extracted images are resized into 128 x128. The UR and MCF data sets are combined in one data set containing a total of 2000 frames. Out of the total, 1000 frames contain fall while the remaining contain no fall.
The fall sequence consists of depth RGB data, which is further labeled as category 0 (No Fall) or category 1 (Fall) [30], [31]. The second dataset is multiple camera datasets that contain 24 different scenarios [26]. The dataset contains falls of various types including forward fall, backward fall, slip, falling on furniture, and falling on a floor.
The current study compared the proposed approach (PA) that is, VGG-16 with state-of-the-art existing networks including ResNet50 and ResNet-101 in terms of percentage accuracy and time efficiency.
VGG-16 outperforms the ResNet-50 and ResNet-101 in terms of percentage accuracy as seen in figure IV-A and table IV-A. As MCF and URFD datasets are combined into a single dataset hence, the dataset shows high intraclass variations. PA showed excellent results in such data of high diversity.
As explained in fig III, the given data input size was 224*224 for conventional layers size of 16 with filter size 3. When it comes to number of feature maps, they were 3512 and for that number of weight and MACS were 14.7M and 15.3G, respectively. Afterwards, the 3 FC layers were included with several weights and MACS 124 and 124M, respectively. The total weights were 138M and MACS were 15.5G.
COMPARISON OF PA WITH RESNET-50, AND RES101 IN TERMS OF PERCENTAGE ACCURACY AND THE TIME EFFICIENCY
|
|
ResNet-50 |
ResNet-101 |
PA |
|
Accuracy |
91.8% |
96.11% |
98.05% |
|
Time (sec) |
2 |
3 |
3 |
It can be seen in figure 7 that PA execution time is comparable with resNet 101. However, resNet-50 shows better time efficiency than PA by compromising its percentage efficiency. Considering this performance of PA in terms of time, it can be safely predicted that this approach can be used later in real-time systems.
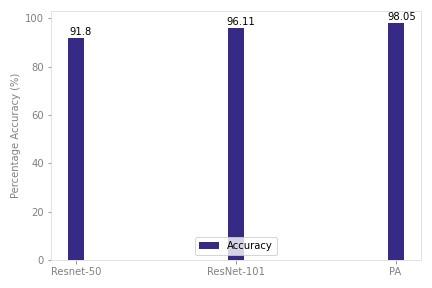
FIGURE 6. Comparison of PA with Existing Deep Networks in terms of Percentage Accuracy
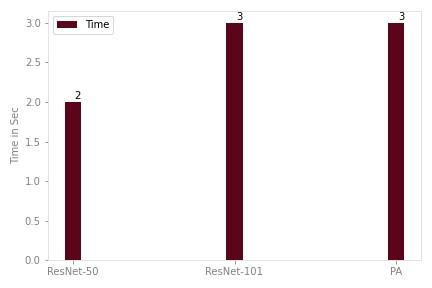
FIGURE. 7. Comparison of VGG-16 with Existing Deep Networks in terms of Time Efficiency
The current study compared the performance of VGG-16 with other deep learning architectures. It concluded that proposed architecture VGG-16 exceeded others both, in terms of percentage accuracy and time efficiency. The work can be further extended to achieve more accuracy on datasets generated in an uncontrolled environment. In the future, deep algorithms would continue to show more promising results. The addition of a large data repository for fall detection would help in further improving the results of the proposed algorithm. Human fall detection in dim light, occlusion, and camouflaged needs to be further investigated. A robust and real-time system that shows even better percentage accuracy and works in an uncontrolled environment is the need of the hour.
We are thankful to Muhammad Irfan Karim, Muhammad Tahir, and Muhammad Kashif who provided their insight to assist our work which greatly improved the manuscript. Our gratitude to anonymous reviewers who provided their suggestions and support.
[1] Z. Uddin, W. Khaksar, and J. Torresen, “Ambient sensors for elderly care and independent living: A survey,” Sensors, vol. 18, Art. no. 2027, June 2018, https://doi.org/10.3390/s1807 2027
[2] Kharrat, E. Mersni, O. Guebsi, F. Z. Ben Salah, and C. Dziri,“Qualite de vie et personnes´ agˆ ees en tunisie,,” NPG Neurol-Psych- Geriat with, vol. 17, pp. 5–11,Feb.2017, https://doi.org/ 10.1016/j.npg.2016.12.001
[3] Khraief, F. Benzarti, and H. Amiri, “Elderly fall detection based on multi-stream deep convolutional networks,” Multimed.ed. ToolsAppl. with, vol. 18pp.1–24,2020, https://doi. org/10.1007/s11042-020-08812-x
[4] R. Burns, J. A. Stevens, and R. Lee, “The direct costs of fatal and non-fatal falls among older adults united states,” J. Saf., vol. 58, p. 99–103, Sep. 2016, https://doi.org/10.1016/j.jsr. 2016.05.001
[5] Center for Disease control and Preverntion, “Cost of injury data. https://www.cdc.gov/injury/wisqars/cost/ (accessed August 22, 2020).
[6] L. Santos, P. T. Endo, K. H. D. C. Monteiro, E. D. S. Rocha, I. Silva, and T. Lynn, Accelerometer-based human fall detection using convolutional neural networks,” Sensors, vol. 19, no. 1, Art. no. 1644, Apr. 2019, https://doi.org/10.3390/s19071644
[7] K. Verma, J. L. Willetts, H. L. Corns, H. R. Marucci-Wellman, D. A. Lombardi, and T. K. Courtney, “Falls and fall-related injuries among community-dwelpng adults in the united states,” PLoS One, vol. 11, no. 3, Art. no. 015093,Mar.2016, : https://doi.org/10.1371/journal.pone.0150939
[8] R. Timsina, J. L. Willetts, M. J. Brennan, H. Marucci-Wellman, D. A. Lombardi, T. K. Courtney, and S. K. Verma, “Circumstances of fallrelated injuries by age and gender among community-dwelling adults in the united states,” PLoS one, vol. 12, no. 5, Art.no.01765612017, https://doi.org /10.1371/journal.pone.0176561
[9] Rosanes, “Revealed – The most common types of insurance fraud.”https://www.insurancebusinessmag.com/us/news/breaking-news/revealed--the-most-common-types-of-insurance-fraud-399325.aspx (accessed Sep. 8, 2020).
[10] Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv,2015, https://doi.org/10.48550/ arXiv.1409.1556
[11] Chaccour, R. Darazi, A. H. E. Hsani, and E. Andres, “From fall detection to fall prevention: A generic classification of fall-related systems,” IEEE Sens. J., vol. 17, no.3,pp.812–822,2017, https://doi.org/10.1109/ JSEN.2016.262809
[12] Singh, S. U. Rehman, S. Yongchareon, and P. H. J. Chong, “Sensor technologies for fall detection systems: A review,” IEEE Sensors Journal, vol. 20, no. 13, pp. 6889–6919, Feb. 2020, https://doi.org /10.1109/JSEN.2020.2976554
[13] F. R. Al-Okby and S. S. Al-Barrak, “New approach for fall detection system using embedded technology,” in 2020 IEEE 24th Int. Conf.Intell.Eng. Sys., 8–10 July 2020, pp. 209–214, https://doi.org/10.1109/ INES49302.2020.9147170
[14] Miaou, S, H. Sung, P, and C.-Y. Huang, “A customized human fall detection system using omni-camera images and personal information,” in 1st Transdiscipl. Conf. Distrib. Diagnosis Home Heal. D2H2, 2–4 Apr. 2006, pp. 39–42,2006, https://doi. org/10.1109/DDHH.2006.1624792
[15] N. Doukas and I. Maglogiannis, “Emergency fall incidents detection in assisted living environments utilizing motion, sound, and visual perceptual components,” IEEE Trans. Info. Techno Biomed., vol. 15, no. 2, pp. 277–289, Nov.2010, https://doi.org/ 10.1109/TITB.2010.2091140
[16] F. Ali, M. Muaz, A. Fatima, F. Idrees, and N. Nazar, “Human fall detection,” in IEEE Int. Conf. Multi Top., 19–20 Dec. 2013, pp. 101–105, https://doi.org/10.1109/INMIC.2013.6731332
[17] F. Ali, R. Khan, A. Mahmood, M. T. Hassan, and M. Jeon, “Using temporal covariance of motion and geometric features via boosting for human fall detection,” Universite de Montr´eal´, vol. 18,Art.no.1918June 2018, https://doi.org/10.3390/s180619 18
[18] Wang, L. Chen, and J. Dong, “Human fall detection in surveillance video based on pcanet,” Multimed. Tools Appl., vol. 75, no. 19, pp. 11603–11613, June 2016, https://doi. org/10.1007/s11042-015-2698-y
[19] Min, H. Cui, H. Rao, Z. Li, and L. Yao, “Detection of human falls on furniture using scene analysis based on deep learning and activity characteristics,” IEEE Access, vol. with2018,pp.324–9335, https://doi. org/10.1109/ACCESS.2018.2795239
[20] Shojaei-Hashemi, P. Nasiopoulos, J. J. Little, and M. T. Pourazad, “Video-based human fall detection in smart homes using deep learning,” IEEE Int. Symp. Cir. Sys., 27–30 May2018,: http://doi.org/10. 1109/ISCAS.2018.8351648
[21] Espinosa, H. Ponce, S. Gutierrez, L. Mart´ ´ınez-Villasenor, J. Brieva,˜ and E. Moya-Albor, “A vision-based approach for fall detection using multiple cameras and convolutional neural networks: A case study using the up-fall detection dataset,” Comput. Biol. Med., Art. no. 103520, Dec. 2019, doi: https://doi.org/10.1016/j. compbiomed.2019.10352
[22] Han, et al, “A two-stream approach to fall detection with mobilevgg,” IEEE Access, vol. 8, pp. 17556–17566, Jan. 2020, https://doi. org/10.1109/ACCESS.2019.2962778
[23] A. Cameiro, G. P. da Silva, G. V. Leite, R. Moreno, S. J. F. Guimaraes,˜ and H. Pedrini, “Multi-stream deep convolutional network using highlevel features applied to fall detection in video sequences,” in Int. Conf. Sys. Sig. Image Proc., 5–7 June 2019, pp. 293–298, https://doi.org/10.1109/ IWSSIP.2019.8787213
[24] LNguyen, D. Lin, Z. Lin, and J. Cao, “Deep cnns for microscopic image classification by exploiting transfer learning and feature concatenation.”IEEE. Symp. Cir. Sys., 27–30 May 2018, pp. 1–5. https://doi.org10.1109/ISCAS.2018.8351550
[25] Sachan, “Detailed guide to understand and implement resnets,” CV-Tricks.com. https://cv-tricks.com /keras/understand-implement-resnets/ (accessed Feb. 27, 2018).
[26] Auvinet, C. Rougier, J. Meunier, A. St-Arnaud, and J. Rousseau, “Multiple cameras fall dataset,technical report 1350,” Universite de´ Montreal, vol. 21, pp. 611–622, 20
[27] Mei, Z. Liu, Y. Niu, X. Ji, W. Zhou, and D. Wang, “A 200mhz 202.4 gflops@ 10.8 w vgg16 accelerator in xilinx vx690t,” in IEEE Glob. Conf. Sig. Info. Proc., 14–16 Nov. 2017, pp. 784–788. https://doi.org/10.1109/Global SIP.2017.8309067
[28] Z. Alom, et al., “The history began from alexnet: A comprehensive survey on deep learning approaches,”arXiv2018, https://doi. org/10.48550/arXiv.1803.01164
[29] Theckedath and R. R. Sedamkar, “Detecting affect states using vgg16, resnet50 and se-resnet50 networks,”,,” ” SN Comput. Sci., vol. 1, pp. 1–7, 2020.fenix, “UR fall detetction dataset.” Fenix.com. http://fenix.univ. rzeszow.pl/mkepski/ds/uf.html (accessed Sep. 2, 2020).
[30] Kepski and Kwolek, Fall detection on embedded platform using kinect and wireless accelerometer,” in Int. Conf. Comput. Handicap. Persons, 2012,pp.407–41. https://doi.org/10. 1007/978-3-642-31534-3_60