Adnan Younas, Muhammad Yousuf Kamal, Sumaira Kausar*, and Samabia Tehsin
Center of Excellence in Artificial Intelligence (COE-AI), Department of Computer Science, Bahria University, Islamabad, Pakistan
* Corresponding Author: [email protected]
Autism Spectrum Disorder (ASD) is a neurodevelopmental disorder that causes disrupted social behaviors and interactions of individuals. Hence, it can adversely affect the social functioning of individuals. Each autistic individual is said to have a sort of unique behavioral pattern. ASD has three major sub-categories, namely autism, Asperger, and pervasive developmental disorder, not otherwise specified. The term spectrum indicates that ASD possesses a large variety of symptoms of severity. Practitioners need to have a vast experience and expertise for the accurate analysis of the symptoms of ASD. These symptoms need to be acquired from a range of modalities. An accurate diagnosis requires the analysis of brain scan and phenotypic data. These aspects present a multifold challenge for computer-aided ASD diagnosis. Most of the existing computer aided ASD diagnosis systems are capable of diagnosing only whether an individual is affected with ASD or not. A detailed categorization into the subcategories of ASD in such diagnosis is missing. Another aspect that is missing in the existing techniques is that symptoms are observed from a single modality. This can adversely affect the accuracy of diagnosis, since different modalities focus on different aspects of symptoms. These challenges and gaps provided the motivation to present a method that covers the variety exhibited in ASD, while considering the dire need of acquiring symptoms from a variety of data sources. The proposed method showed rather encouraging results. Moreover, the achieved results are evident of the efficacy of the proposed method.
INDEX TERMS Asperger, Autism Spectrum Disorder (ASD), diagnosis, feature fusion, machine learning, psychiatry
JEL CODES H51, H52, and H53
A person with autism lacks social communication and is involved in repetitive behaviors [1]. The term ‘spectrum’ describes the range which may vary from mild to severe levels of disabilities in skills and behaviors [2]. Regardless of race, ethnicity, culture, and socioeconomic background, the basic signs of Autism Spectrum Disorder (ASD) are lack of social interaction and repetitive behavior [2]. ASD is a neurodevelopmental disorder that affects the verbal and social skills of an individual with no discrimination of age, gender, race, or any other social background. Autism growth around the globe has made researchers work on early diagnosis and treatment to make the effected individual an active part of society again. Automated diagnosis of ASD is of dire need of the time. Early and speedy diagnosis can help patients in their early treatment. With the emergence of AI technology, the treatment of ASD has become possible that would not only be beneficial for patients, however, for all other stakeholders as well.
According to the diagnostic and statistical manual of mental disorder 4th edition (DSM-IV), autism has different types including autistic disorder, Asperger disorder, childhood disintegrative disorder, and pervasive developmental disorder not otherwise specified [3, 4]. This was the actual diagnostic classification of DSM-IV published by the American Psychiatric Association in 1994. In 2013, DSM-IV was upgraded to 5th edition as DSM-5 in which all these types except Rett syndrome were combined to make it"spectrum" with a range from mild to severe [1]. Different studies have discovered that both, genetic and environmental factors are responsible for restriction in the development of the brain and may cause autism due to changes \ in cerebellar architecture and abnormalities in the limbic system [1]. No clear causes are found for autism, however, there are several misconceptions about its causes [5]. There are some common parental beliefs regarding the causes of autism. Parents believe that ASD in their child is either due to their child’s brain structure, environmental pollution, and genetic problems, or maybe the will of God. Some parents associate it with generalized stress, bad luck, poor diet, and tobacco or alcohol consumption [6]. There is no connection between vaccination and autism [5], however, many parents feel that vaccines have toxins that cause autism. Diagnosis of autism is not that easy since clinicians have to depend on personal observation and information provided by parents. [5, 6].
Several screening tools including "STAT" (screening tool for autism in toddlers), ‘’ADOS" (autism diagnostic observation schedule), "ADI-R" (autism diagnostic inter- view revised), and "DISCO" (a diagnostic instrument for social communication disorders, UK) are available[2]. Some other tools are, "modified checklist for autism in toddlers revised, with a follow up" (M-CHAT-R/F)" survey of the well-being of young children". Some other tools are also available to measure social deficiencies, such as "Social Communication Questionnaire (SCQ)", "Social Responsiveness Scale (SRS)" and "Autism Spectrum Screening" questionnaire. All such tools are based on personal observations, interviews, and questionnaires which are fairly questionable in the context of reliability. Several societies prefer genetic testing in which different laboratory tests are performed, such as CBC, (complete blood count), urine examination, and stool analysis. Brain images are not a common practice, however, autism’s relationship with brain urges the clinicians to get neuroimages through MRI for detailed analy sis [1].
With the advancement in the field of neuroscience and psychopathology, early detection of ASD is possible [7]. ASD has some similar symptoms to other disorders, such as ADHD that makes screening difficult. Early detection of autism can help clinicians treat the patient at an early stage. [8] ASD is a result of genetic mutation [9]. Most studies suggest that very few patients are diagnosed at an early age, although it is proven in studies that diagnosis under the age of three has a stability rate of 100%. [10] Several studies have used automated methods based on computer vision techniques and data analysis for diagnosis of ASD [7–9].
ASD is diagnosed clinically with different tools including STAT, ADOS, ADI-R, CARS, SRS, and SCQ [2]. Iidka [12] applied neural networks to classify teenager ASD patients and obtained 90% accuracy. Chen et al. [13] used SVM and classified 79.17% of cases accurately. [14] obtained 73.4% accurate results with CNN in which a novel approach was proposed by using full resolution 3D spatial structure of rs-MRI data. Moreover, ABIDE dataset was also used for binary classification and an accuracy of 73.3% was obtained. Li et al. [15] applied deep neural networks in a 2-stage method for the classification of ASD in which fMRI images were used through a 3D CNN sigmoid classifier with an accuracy of 85.3%. Moreover, the problem of interpretation of reliable biomarkers was also addressed which was related to ASD classification, however, rs-FMRI images were used for binary classification.
Heinsfeld et al. [16] identified the most influential areas of brain that causes ASD with an accuracy of 70% by using DNN. Autoencoder increases the performance of model and classifiers, such as RF, SVM, and DNN showed accuracies of 63%, 65%, and 70%, respectively. Brain images from ABIDE dataset were used to differentiate ASD patients from non-autistic people. Yang et al. [17] classified ASD and TD with the help of rs-fMRI by using tensor flow-based DNN models and obtained an accuracy of 75.27%. Resting- state fMRI was used, acquired from multi-site, through ABIDE repository for conducting the study. Moreover, images data was used for binary classification of ASD and no ASD. Behavioral- based features were not used. Yin et al. [18] reviewed fMRI and sMRI based diagnosis of ASD.
Arya et al. [19] used feature fusion of behavioral and brain images data from and with the help of GCN framework. They fused brain summaries obtained from 3D CNN with phenotypic data to make the model more effective. A mean accuracy of 64.23% was achieved. The study focused on binary classification. [20] applied a deep neural network for the diagnosis of ASD patients by using brain images dataset. Their study employed a hybrid model of unsupervised autoencoders and supervised CNN and obtained an accuracy of 84.05%. Pominova et al. [21] performed domain adaptation on brain images data for the classification of ASD patients based on brain pathology. Their approach outperformed other existing approaches with the use of 3D convolutional autoencoders. Lu et al. [22] proposed a fuzzy multi-kernel clustering approach based on autoencoders and an accuracy of 61% was obtained by combining the fMRI and phenotypic data. Their clustering approach performed better than others for the diagnosis of ASD.
Huang et al. [23] used ABIDE-I multi- site and multi-template data and classified ASD patients by using brain image features and achieved an accuracy of 89.13% . In 2018, Khosla et al. [9] used functional MRI and obtained an accuracy of 73.3% for binary classification of ASD patients. However, a large number of studies have been conducted for boosting the performance of autism classification by using different data processing techniques [24].
It is evident from the literature of automated ASD diagnosis that some areas require more focus in the research. One of the key observation in this regard is that majority of the work in literature is focused on binary classification, that is, ASD effected and control classes. Very less to none work has been done in the classification of sub categories of ASD. Another related research dimension that requires more attention is multi-modal data analysis for diagnosis. The current study focused on these two aspects. The proposed method focuses on classification into subcategories of ASD and it also considered multiple modalities to take symptoms. Moreover, the achieved results were promising.
Many datasets are available for ASD patients. Kaggle, UCI machine learning, and different self-collected datasets are available on different sites. However, an initiative by the "National Institute of Mental Health America" has made a repository of autism patients’ data with controls. This data is publicly available on the NIMH website for further research. It is a multi-modal data with considerable number of records. It is a multi-site global ASD data collected from different states of America and other sites over the world. This data features brain images that plays an important role in the diagnosis of ASD .
Some other sites have images data sets but they lack behavioral and functional data. This data set comprises of clinical as well behavioral data sets. In many other data sets, data is available just for infants, adolescents, or adults separately, however, here in this initiative, all ranges of age are covered in a single data set. Moreover, most datasets are related to men, while ABIDE deals with both genders. Hence, global participation has made it more diverse and effective in generalizing the diagnosis process around the globe.
This data repository is presented by International Neuroimaging Data-sharing Initiative (INDI). It has two data sets named ABIDE-I and ABIDE-II. Each data set comprises of brain images taken at different laboratories over the world. Hence, it should be taken into consideration that these images are taken with different MRI machines and in different settings. ABIDE-I was released in 2012 with 1112 records of 17.
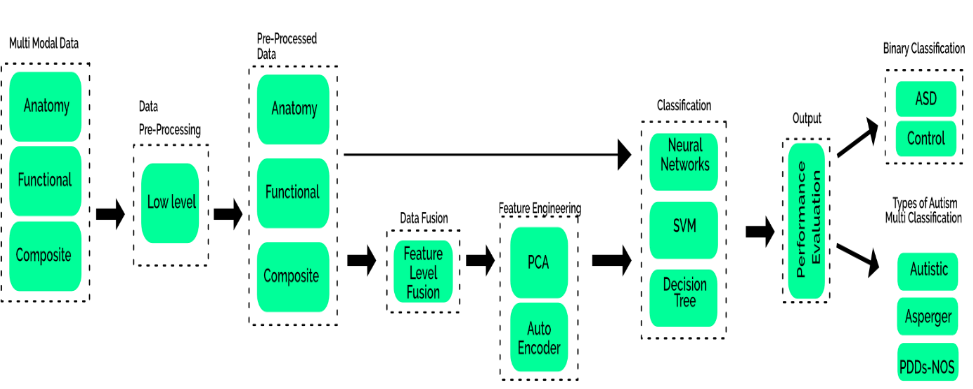
FIGURE 1. Proposed model
Figure 1 proposed model global sites. It includes resting state functional magnetic resonance imaging (rs-fMRI), phenotypic data with functional data from INDI. It comprises of 573 individuals with no autism (controls) and 539 ASD patients with an age ranging from 7-64 for both genders. In June 2016, ABIDE initiative released its second edition with 521 ASD patients with 593 controls with an age ranging from 5-64 from 19 global sites. This data set had 1114 total records with more phenotypic features, especially correlated with ASD and its symptoms. ABIDE-II data set presented more psychopathological phenotypic features to dis- criminate ASD from other similar diseases. [25] ABIDE-II data set had 1114 records collectively. In individual anatomy modal (Anatqap) had 1359 records including follow-up and records of longitudinal samples. Functional modal had 1449 records including follow-up sessions as well ,while composite modal comprising of clinical observations and behavioral data related to any individual who contributed to data collection research had 1114 records. To make it universal, extra records of follow- up and longitudinal samples were eliminated.
Behavioral and clinical diagnosis is included in a composite file with a large number of personal, behavioral, and DSM-5 manual records. ABIDE-II has psychopathological data of patients and controls with brain images numerical features. There are two modalities for this purpose. One is Anatqap which is an anatomy modality It contains structural brain images features, while the other is functional qap which contains functional fea tures of the brain of ASD patients and controls.
B. DATA PRE-PROCESSING
Data pre-processing is a necessary step to go through before feeding the data into main classifier. Unprocessed data creates many ambiguities in the proper classification. Processed data works more effectively and efficiently. In the data description, several missing values were mentioned along with some follow-ups and sessional samples that were included in different modalities. DTI modality was excluded due to less number of records, while others still had many imbalances. For this purpose, data pre-processing was conducted. A single session was used and all follow-ups were skipped. All values with missing records in any modality were removed. Moreover, any feature with missing records was not considered to avoid any misinterpretation. Each modality was individually treated and records were removed that were missing in other modalities. Figure 1 explains the pre-processing steps taken in this study.
1) FEATURE SELECTION
First of all, all the missing values were checked and removed. Due to medical data, it was not possible to replicate the data augmentation since it can be misguiding and may misinterpret the results. Each modality was dealt separately. In this modality, three different scores regarding IQ were included. However, due to missing values its average was decided to be used. AIQ score was made and all average scores were put in this column. After all the pre-processing, 1026 records were obtained in all three files which were the same and complete in all modalities. Autism was classified into sub-classes of autistic, Asperger, and PDDs-NOS as discussed by DSM-IV which was later combined to make autism a"spectrum" with mild to severe range. All the missing values were removed and 589 records were obtained with sub-class classification labels. The current study focused to classify ASD patients into further sub-classes of autistic, Asperger, and PDDs-NOS. For the three-class multi-classification of ASD patients without controls, another data subset of ASD patients with 271 records was obtained.
2) DATA NORMALIZATION
After dealing with missing values and feature selection, data normalization was performed since there was a diverse variety of data ranges having different features. Some attributes had very small values ranging between 0 and 1, while others had range of hundreds. This diversity can adversely affect the classification method. Therefore, data normalization was performed. There are several techniques to perform data normalization. Min Max approach was employed to normalize the data between 0 and 1.
C. FEATURE LEVEL FUSION OF DATASETS
The process of data fusion is commonly performed to get the combined effect of attributes. Sometimes, data inferences are incomplete without some other attributes. Hence, fusion helps to fill this gap. Fusion of data is performed at a different level. It can be performed at the feature level as well as at the final stage of decision, as [1] proposed a model of adaptive boundaries by using fusion of classifiers which improved the results significantly [1]. Feature level fusion is the combination of features acquired from different modalities. This fusion helps to get the collective effect of these diverse attributes and hence, makes the classification more robust, effective, and accurate. In this way, features are observed collaboratively and the decision is made based on all combined attributes.
D. CLASSIFICATION
Classification refers to make groups of data according to particular labels. Classification is performed for separating objects differently from others. Machine learning can be used for automated classification of ASD subcategories. In literature, majority of the work is focused on binary classification of patients into autistic and control classes. In the current study, three different experimental setups were employed for classification.
C(X)→y where C is the classifier
X= Xs U Xf U Xp
→Xs ∈ →S and →Xf∈ →F , and →Xp∈ → P
→S = (s1:sn) (Structural MRI indicators)
→F= (f1:fn) (Functional MRI indicators)
→P = (p1:pn) (Phenotypic indicators)
y ∈ →Y
→Y = (y1 y2) (for Binary classification)
→Y = (y1 y2 y3) (for 3 class classification)
→Y = (y1:y4) (for 4 class classification)
Table I describes the number of samples for binary, 4-class multiclass classification, and 3-class multiclass classification.
A. EXPERIMENTAL SETUP
ABIDE-II dataset was used for the experimentation. "Google Collaborator" (Google Colab) was used to perform the experiments. The virtual machine which was used for Collaboration had 13GB RAM and 2 v CPU with 2-core Xeon 2.2GHz. To evaluate the performance of the models, a classification report was used to mention accuracy with precision . The weighted average score of all measures of precision were compared and recalled.
B. DATASET
ABIDE dataset showed total samples of 1114 with 521 ASD patient samples and 593 control records. After pre-processing, 1026 records were obtained. For the training of classification models, the data was split into 70% for training, 10% for validation, and the remaining 20% was used for testing the model. In some experiments, a 60-10-30 training-validation- test split was also used, however, results with a 70- 10-20 ratio were encouraging. For binary classification, the data was distributed including 718 samples for training, 103 samples for validation, and 205 samples for testing. In multi-class classification, there were 589 records and the data was distributed among 412 records for training, 59 records for validation, and 118 records for testing purposes. In performing the sub-classification of ASD patients without controls, there were 271 records which, again, was split with the same ratio as 189 samples for training, 28 samples for validation, and 54 records for testing the model. Each ML model would be discussed with different hyper-parameters. The settings for each classifier would be discussed in- dependently.
C. CLASSIFICATION
Machine learning methods are used for ASD classification. Experimentation was performed on three well established classifiers, that is, Decision tree (DT), Support Vector Machine (SVM), and Artificial Neural Networks (ANN).
TABLE I
CLASSIFICATION WITH TOTAL NUMBER OF RECORDS
|
No. |
Classification |
Samples |
Classes |
|
1 |
Binary Class |
1026 |
2-Class |
|
2 |
Multi-Class |
589 |
4-Class |
|
3 |
ASD Sub-Class |
271 |
3-Class |
1) DECISION TREE (DT)
A Decision Tree (DT) is a machine learning model that is used as a classifier to classify the binary or multiclass method. It examines the goodness of given attributes to perform classification. Best node takes the root position and rest are ranked and positioned in the tree according to their goodness value. Root nodes are the classes. Purity of the node is the criteria for the goodness of the nodes. To conduct the current study, purity measures were used, that is, entropy and Gini index. The formula for both is given below:
Gini= (ci)
Entropy = (ci) * log2 (p (ci))
Where, p (ci) is probability or percentage of class (ci) in a node. In DT,"Gini" and "Entropy" were used as criteria with a max depth of 5. The model was fine-tuned with different parameters and resultantly, the model performed well with 70% training samples and"Gini" as a criterion with a depth of 5.
2) SUPPORT VECTOR MACHINES (SVM)
Support Vector Machine (SVM) is a machine learning model used for classification. It works with mathematical functions called"Kernel". This method makes vectors of different groups along a threshold and each value is grouped into its particular vector. SVM is one of the leading classifiers. In SVM, different kernels are used. Four different kernels were used including Linear, Polynomial, Sigmoid, and Radial Base Function (RBF). Different hyper-parameters were also used. The value of "C" error term was also set in linear to 50 and in RBF to 100 in order to avoid over-fitting. In RBF, the value of "gamma" was set to 1 in order to make sure that the model uses a low value to get the influence of each training example as far as possible. In polynomial kernel, the polynomial degree was set to 8 as going to higher values takes enough time to run one instance. The train test split was 70-10-20, however, 60-10-30 ratio was also experimented.
Some of the basic kernels used in SVM are given below with their mathematical equations.
Linear:K(x,y) = x.y
Polynomial: K(x,y) = (1+x.y)d
RBF: K(x,y) = exp(-a||x-y||)2
Sigmoid: K(x,y) = tanh(ax.y+b)
3) NEURAL NETWORKS (NN)
A neural network (NN) is one of the most popular classifier. It takes inspiration from the structure and working of human brain. The idea behind neural network was "neuron" which is a basic unit of brain. There is some activation function that processes the data with checking of error and updating its weight. Gradually, machine learns and error is minimized. In NN, an activation function refers to a mathematical function that maps inputs to the neuron to output of that neuron. Table II shows different activation functions with equations and derivatives. Backpropagation is used to learn the parameters of the network. Backpropagation uses gradients to optimize the parameters.
In the NN model, a simple model having input, hidden, and output was used. For binary classification, sigmoid in output and rectified linear unit (Relu) function in hidden layers were used. The Tangent Hyperbolic function in input and hidden layers was also tested. To compute the loss, Binary Cross entropy with "Adam" as an optimizer was used. Stochastic gradient descent (SGD) was also tested, however, it didn’t perform well. The batch size was set to 200 with 1000 epochs to in order to run the model for sufficient training and prediction. 10-fold cross-validation was used to enhance model efficiency. In multi-class classification, the same model was used with the same parameters, however, the activation function was changed to "Softmax" for multi-class classification.
TABLE II
DERIVATIVES OF ACTIVATION FUNCTIONS
|
No |
Function |
Equation |
Derivative |
|
|
1 |
Sigmoid |
σ(x)=1/(1-e(-x)) | f'(x)=f(x)(1-f(x))2 | |
|
2 |
TanH |
σ(x)=(ex- e(-x))/(ex+ e(-x)) | f'(x)=f(x)(1-f(x))2 | |
|
3 |
ReLu |
f(x)={(0 if x <0 x if x ≥ 0) | f'(x)={(0 if x<0 1 if x ≥ 0) | |
|
4 |
Softmax |
f(x)=ex/(∑1j+ex) | f'(x)=ex/(∑1j+ex)- (ex)2/((∑1j+ex)2 |
Performance evaluation of machine learn ing models is mandatory to assess the model efficiency. The current study, worked on accuracy, precision, and recall. Accuracy is the most common measure used to assess the performance of classifiers in machine learning. However, when the data set is imbalanced, accuracy cannot predict model performance alone and it is important to consider other measures to get a clear picture of model performance. The current study used accuracy, precision, and recall to get a deep insight into model performance since the data was imbalanced, however, with a little skewness.
T P + T N
Accuracy =
T P + F P + T N + FN
T P
Precision =
T P + F P
T P
Recall =
T P + F N
All three models were evaluated through evaluation metrics. The dataset was imbalanced, therefore reliability on accuracy was not sufficient and it was better to check other measures, such as precision and recall. In feature fused modality, weighted averages of all these measures were obtained. The results in binary classification showed that SVM and neural networks performed better than a DT. About 95±3 % were obtained in each measure of accuracy, precision, and recall in SVM. In the NN, the best results of 97±1% were obtained, however, 81±2% in DT for all measures. In 4-Class Multi-classification, DT performance was better than both SVM and NN. DT showed 83±3% and SVM showed 83% in precision and 82% accuracy and recall. However, NN showed a 77% result. It has been observed that DT’s precision and accuracy were better than SVM and NN. Finally, in 3-Class Multi-classification of ASD patients without controls, NN, DT, and SVM performed nearly similarly and showed 89% in both SVM and NN, while 87% accuracy and recall in DT with 88% precision. Here, DT results remained a little lower than SVM and NN for all measures.
The first step of the current study was to classify ASD and controls which remained the focus of previous studies. Targeting Dx group with two labels, samples were classified in individual modal and in the proposed method of feature fusion modal. The current study proved that the proposed approach outperformed individual modalities in all classifiers. Results showed that feature fusion of multi-modality data gave the best results. The next step was to classify ASD and controls into broad multi-classes of no autism, autistic, Asperger, and PDDs-NOS, which remained a gap in previous studies. Targeting "PDD DSM IV" with four labels, samples were classified in individual modalities as well as in the proposed method of feature fusion approach. Results showed that the approach outperformed without feature fusion in DT and SVM. Behavioral data showed the same results in NN in precision, however, remained lower in accuracy and recall. Results showed that feature fusion gave better results in all classifiers.
Finally, the main focus of the current study was to classify ASD patients into subcategories which were mostly not discussed in the previous studies. "PDD DSM IV" were targeted with three labels. Samples were classified in individual modalities and in the proposed method of feature fusion approach. Achieved results showed that feature fusion gave the better results.
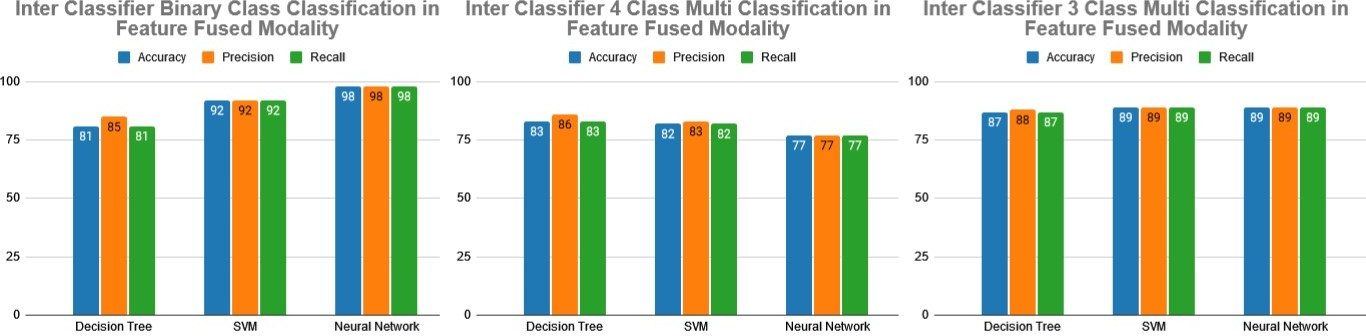
FIGURE 2. Analysis of feature fusion
The current study attempted to use feature engineering for fused data in order to improve the results, however, the research showed that the use of PCA and auto encoder was not helpful in this case. Experiments proved that feature reduction declined in NN to 55%. Finally, the proposed approach of feature-fused modal outperformed all individual modalities. With an average of 95±3% in all measures, fused dataset performed best both in SVM and NN. However, in DT, its performance remained at 82±3%, however, still, it is better than individual modality results. SVM, DT, and NN performed differently in binary classification. In the proposed method, NN remained at the top with an average of 98% in each measure, while SVM showed 92% overall. However, DT results declined to 63±4% in all individual modalities. It declined the results further, proving that no more feature engineering was helpful and preprocessing was done already which was good enough to classify the data. Any reduction or transformation of the features would not be helpful and it is better to use features in the same space since any such effort can adversely affect the overall classification.
ABIDE-II has different modalities of anatomy, functional and behavioral data. The experiments conducted on all modalities individually prove that fusion of all features performs better than considering just functional features of brain images data (anatomy).
The purpose of conducting this research was to sub-classify the ASD patients into sub- categories. At final level, control samples were removed with theselection of ASD patients to classify them into autistic, Asperger, and PDDs-NOS. The experiments conducted on all modalities individually proved that fusion of all features performs better than considering just behavioral or brain images which remained the focus of the majority of previous studies. In ASD patient sub-classification, the anatomy modality showed 62% accuracy and recall in SVM with 64% precision. However, its results declined in DT to 51%. While, precision in NN was enhanced to 63%. Functional modality performed best in DT with 71% precision and 69% in all other measures, however, the results in NN declined to 56%. Functional modality performance in DT remained best at 69±2%. The behavioral data has an average performance of 54 ±2% in NN for each measure of accuracy and recall. The behavioral data modal performed better in SVM than NN which showed 56% result in all measures. Behavioral data results declined adversely in DT to 44% accuracy and recall, while precision showed 49%. Finally, the proposed approach was used and the results of feature fused modal performed best than all individual modalities with an average of 89±1% for all measures in SVM and NN. The fused dataset performed best both, in SVM and NN, However, in DT its performance showed a slight difference of 1% with 88% for precision and 87% accuracy and recall. Here, still, it is better than individual modalities in precision and accuracy. The main objective of this study was to classify ASD patients into further subclasses. In the proposed method, DT showed an average of 87±1% accuracy and recall in feature fused modality, however, the results of DT declined badly in anatomy and behavioral modalities. In behavioral and functional modality, accuracy and recall remained at 51±2%. While, overall SVM performed best with 62±2% in individual modalities for each measure except for the fused feature approach where SVM results outperformed all individual modalities with 89% for each measure. While, NN results were similar for each measure in all functional and behavioral modalities ,leveled at 56% except fused modality where results remained best with 89% and outperformed individual modalities. Figures 3, 4, and 5 show accuracy, precision, and recall for all modalities with each classifier performance.
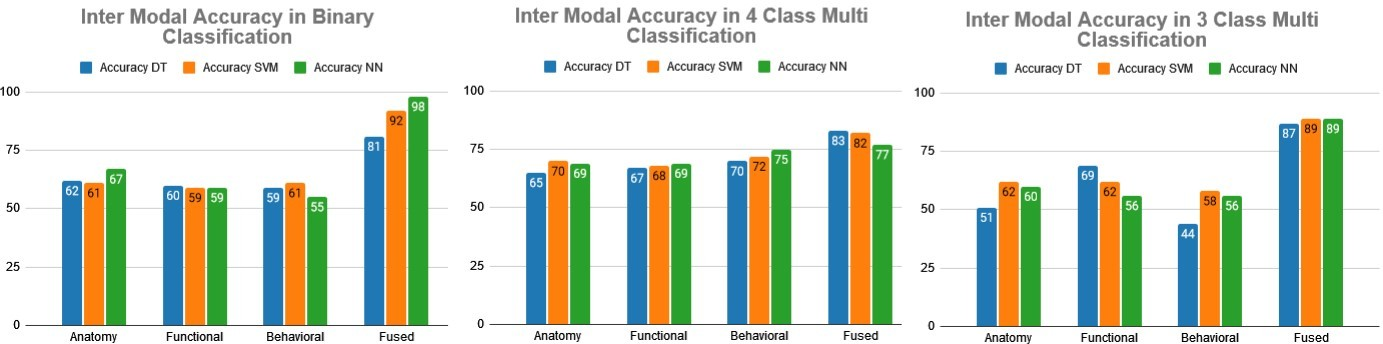
FIGURE 3. Inter modality accuracy comparison in binary and multi-class classification
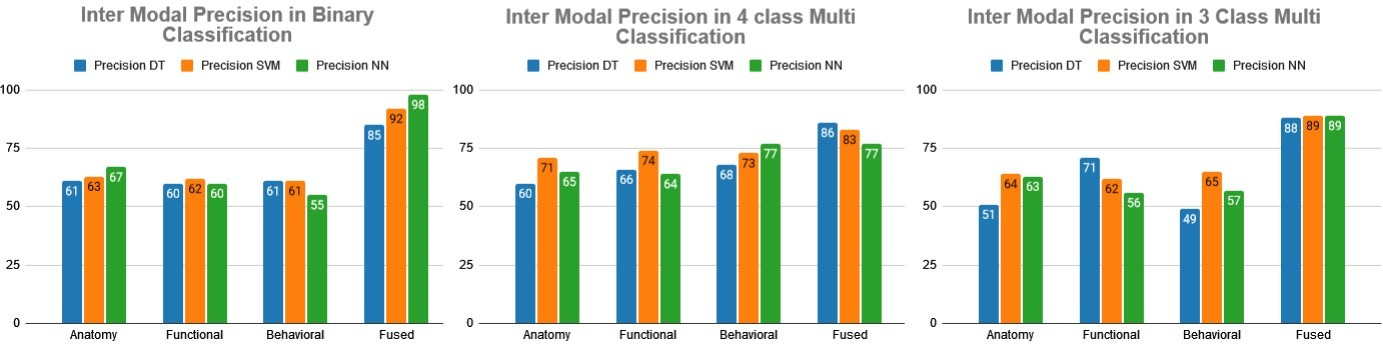
FIGURE 4. Inter modality precision comparison in binary and multi-class classification

FIGURE 5. Inter modality recall comparison in binary and multi-class classification
Arya et al. [19] classified ASD patients by using feature fusion of fMRI and sMRI features of ABIDE-I+II data with a mean accuracy of 64.23%. The proposed feature fusion method classified ASD with a 98% accuracy. A study conducted by Rakic´ et al. [24] also used ABIDE-I by fusing fMRI and sMRI features at decision level and diagnosed ASD patients with an ensemble accuracy of 85.06%. The research conducted by Huang et al. [23] used ABIDE-I multi-site, multi-template data, and classified ASD patients by using brain image features showing an accuracy of 89:13% and recall of 91%. In 2018, Khosla et al. [14] used functional MRI from both ABIDE-I and II and obtained an accuracy of 73.3% for binary classification of ASD patients. Figure 6 represents a comparative result summary on ABIDE data fusion.
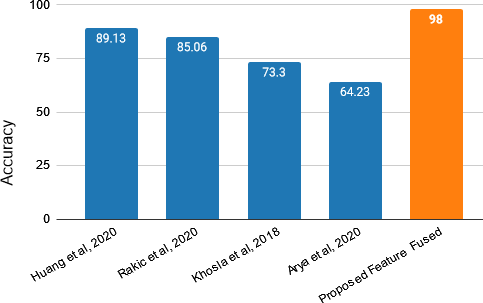
FIGURE 6. Comparative result summary on ABIDE data fusion
The current study achieved its objective to providing an effective automated diagnosis of ASD and its sub-classification. The proposed method of feature fusion of multi-modalities data can help in more accurate and effective sub-classification of ASD patients. Results showed that this feature level fusion is more effective in the diagnosis and sub-classification of ASD patients. This method can help clinicians in cross-validation of their clinical diagnosis with the results of speedy ML models. The diagnosis of ASD with 98% results is good enough to be used even in clinical practices, while classification into subcategories with 89% result is also quite encouraging. There are some future directions to work with the ABIDE-II dataset. Although, the data set provides enough information, however, there are still ways for improvement. Due to its heterogeneity, multi-modality data can be used for generalizing ASD diagnosis including developing countries’ data which is not included in this repository yet. Additionally, many attributes in behavioral modality have missing records and if these missing records are made available, it may help to take more attributes from behavioral data which has a key role in ASD diagnosis. Moreover, in DSM-5, ASD is considered as a spectrum and patients are classified with a varying range of" mild" to"severe". Hence, the use of machine learning models to multi-modality data, in order to estimate the severity range of the autism spectrum would be a challenging task and can be a prospect for researchers.
[1] Hodges, C. Fealko, and N. Soares, "Autism spectrum disorder: Definition, epidemiology, causes, and clinical evaluation,"Transla. Pediat., vol. 9, no. Suppl 1, pp. S55–S65, Feb. 2020, doi: https://doi.org/10. 21037/tp.2019.09.09
[2] Mannion and G. Leader, "Attention-deficit/hyperactivity disorder (AD/HD) in autism spectrum disorder,"Res. Autism Spec. Disord., vol. 8, no. 4, pp. 432–439, Apr. 2014, doi: https://doi.org/10.1016/j.rasd. 2013.12.021
[3] Yirmiya and T. Charman, "The prodrome of autism: early behavioral and biological signs, regression, peri- and post-natal development and genetics,"J Child Psychol. Psych., vol. 51, no. 4, pp. 432–458, Jan. 2010, doi: https://doi.org/10.1111/j.1469-7610 .2010.02214.x
[4] M. Rahman, O. L. Usman, R. C. Muniyandi, S. Sahran, S. Mohamed, and R. A. Razak, "A Review of machine learning methods of feature selection and classification for autism spectrum disorder,"Brain Sci., vol. 10, no. 12, Art. no. 949, Dec. 2020, doi: https://doi.org/10.3390/brainsci10120949
[5] P. Goin-Kochelet al., "Beliefs about causes of autism and vaccine hesitancy among parents of children with autism spectrum disorder,"Vaccine, vol. 38, no. 40, pp. 6327–6333, Sep. 2020, doi: https://doi.org/10.1016/j.vaccine.2020.07.034
[6] M. Brewtonet al., "Parental beliefs about causes of autism spectrum disorder: An investigation of a research measure using principal component analysis,"Res Autism Spect. Disord., vol. 87, Art, no. 101825, Sep. 2021, doi: https://doi.org/ 10.1016/j.rasd.2021.101825
[7] Z. Guo, "Automated autism detection based on characterizing observable patterns from photos,"IEEE Trans. Affect. Comput., 2020, doi: https://doi.org/10.1109 /taffc.2020.3035088
[8] N. Constantino and T. Charman, "Diagnosis of autism spectrum disorder: reconciling the syndrome, its diverse origins, and variation in expression,"Lancet Neurol., vol. 15, no. 3, pp. 279–291, Mar. 2016, doi: https://doi.org/10.1016/s1474-4422 (15)00151-9
[9] Thabtah and D. Peebles, "A new machine learning model based on induction of rules for autism detection,"Health Inform. J., Art. no. 146045821882471, Jan. 2019, doi: https://doi.org/10.1177/1460458218824711
[10] Guthrie, L. B. Swineford, C. Nottke, and A. M. Wetherby, "Early diagnosis of autism spectrum disorder: stability and change in clinical diagnosis and symptom presentation,"J. Child Psychol. Psych., vol. 54, no. 5, pp. 582–590, Oct. 2012, doi: https://doi.org/10. 1111/jcpp.12008
[11] Woolfenden, V. Sarkozy, G. Ridley, and K. Williams, "A systematic review of the diagnostic stability of Autism Spectrum Disorder,"Res. Autism Spect. Disord., vol. 6, no. 1, pp. 345–354, Jan. 2012, doi: https://doi.org /10.1016/j.rasd.2011.06.008
[12] Iidaka, "Resting state functional magnetic resonance imaging and neural network classified autism and control,"Cortex, vol. 63, pp. 55–67, Feb. 2015, doi: https://doi.org/10. 1016/j.cortex.2014.08.011
[13] P. Chenet al., "Diagnostic classification of intrinsic functional connectivity highlights somatosensory, default mode, and visual regions in autism,"NeuroImage, vol. 8, pp. 238–245, 2015, doi: https://doi.org /10.1016/j.nicl.2015.04.002
[14] Khosla, K. Jamison, A. Kuceyeski, and M. R. Sabuncu, "3D convolutional neural networks for classification of functional connectomes," in Proc. Deep Learn. Med. Image Anal. Multimodal Learn. Clinic. Deci. Granada, Spain, Sep. 20, 2018, pp. 137–145.
[15] Li, N. C. Dvornek, J. Zhuang, P. Ventola, and J. S. Duncan, "Brain biomarker interpretation in ASD using deep learning and fMRI," InInt. Conf. Med. Image Comput. Comput-assist. Interven., pp. 206-214. Granada, Spain, Sept. 16-20, 2018, pp. 206–214.
[16] S. Heinsfeld, A. R. Frano, R. C. Craddock, A. Buchweitz, and F. Meneguzzia, "Identification of autism spectrum disorder using deep learning and the ABIDE dataset,"NeuroImage, vol. 17, pp. 16–23, Jan. 2018, doi: https://doi.org/10.1016/j.nicl.2017.08.017
[17] Yang, P. T. Schrader, and N. Zhang, "A deep neural network study of the abide repository on autism spectrum classification,"Int. J. Adv. Comput. Sci. Appl., vol. 11, no. 4, 2020, doi: https://doi.org/10.14569/ijacsa.2020.0110401
[18] Yin, S. Mostafa, and F. Wu, "Diagnosis of autism spectrum disorder based on functional brain networks with deep learning,"J. Comput. Biol., Oct. 2020, doi: https://doi.org/10.1089/cmb.2020.0252
[19] Arya et al., "Fusing structural and functional MRIs using graph convolutional networks for autism classification," inMed. Imag. Deep Lear., 2020, pp. 44–61.
[20] Sewani and R. Kashef, "An Autoencoder-Based deep learning classifier for efficient diagnosis of autism,"Children, vol. 7, no. 10, Art. no. 182, Oct. 2020, doi: https://doi.org/10.3390/children7100182
[21] Pominova, E. Kondrateva, M. Sharaev, A. Bernstein, E. Burnaev, "Fader networks for domain adaptation on fmri: abide-ii study," in 13th Int. Conf. Mach. Vision, Rome, Italy, Nov. 2–6, 2021, pp. 570–577, doi: https://doi.org/10.1117/12.2587348
[22] Lu, S. Liu, H. Wei, and J. Tu, "Multi-kernel fuzzy clustering based on auto-encoder for fMRI functional network,"Expert Syst. Appl., vol. 159, Art. no. 113513, Nov. 2020, doi: https://doi.org/10.1016/j.eswa.2020.113513
[23] Huanget al., "Self-weighted adaptive structure learning for ASD diagnosis via multi-template multi-center representation,"Med. Image Anal., vol. 63, Art. no. 101662, Jul. 2020, doi: https://doi.org/10. 1016/j.media.2020.101662
[24] Rakić, M. Cabezas, K. Kushibar, A. Oliver, and X. Lladó, "Improving the detection of autism spectrum disorder by combining structural and functional MRI information,"NeuroImage, vol. 25, Art. no. 102181, 2020, doi: https://doi.org/10.1016/j.nicl.2020.102181
[25] Di Martinoet al., "Enhancing studies of the connectome in autism using the autism brain imaging data exchange II,"Sci. Data, vol. 4, no. 1, Art. no. 170010, Mar. 2017, doi: https://doi.org/10.1038/sdata.2017.10