Addressing Fisheries Policies in Pakistan Using Deep Learning
Hinna Hafeez1, Arqam Tariq2*, Zaib un-Nisa1, and Farah Taj
1Superior University, Lahore, Pakistan
2Government of the Punjab, Pakistan
Abstract
Pakistan has been facing an acute decline in the aquamarine population, especially fisheries, over the last few years. Therefore, the current study attempted to facilitate policymakers in identifying and addressing fish shortage using Artificial Intelligence (AI), particularly deep learning (DL). Policymakers can achieve this objective with the help of biologists and experts working in the field of AI. Presently, manual identification methods are still utilized in fish breeding, however, aquaculture is the only sector where the use of DL is increasing rapidly. For this, marine biologists and ichthyologists must have a precise taxonomy of fish species, if they intend to understand fish behavior deeply. Most current algorithms are designed to recognize fish in dry environments due to various challenges, such as background noise, picture distortion, the existence of other water bodies in images, low image quality, and occlusion. Due to the rapid growth of DL, the use of computer vision in agriculture and farming to generate agricultural intelligence has become a current hotspot in the field of research. Automatic classification of fish is severely limited by the inability to reliably distinguish between different fish species and taxonomic groups. Once the data is split into a "train" and "test" set, the former's features may be retrieved. Layer-specific feature extraction was performed for the current study. Subsequently, the model was trained using AlexNet and several machine-learning classification methods were compared to improve the classification accuracy. To demonstrate the use of DL in order to address the extinction of fisheries in Pakistan, a dataset of different types of fish was used, taken from Kaggle which measured 541MB. After choosing the dataset, AlexNet was used for the classification and to split the data into test (70%) and train data (30%). Afterwards, the features of train data were extracted on layers and AlexNet was used to train the model. Later, different machine learning classification algorithms were used to find the best classification accuracy, which may help to identify the fish breeds that are facing the threat of extinction. Moreover, policymakers may use the results to formulate policies in order to address the problem.
1. Introduction
The maximum number of fish ever caught was 178 million tons in 2020 globally[1], of which human consumption accounted for 88%. This is crucial for the UN Food and Agriculture Organization (FAO)'s goals to achieve its objective of reducing hunger and malnutrition around the world Iqbal et al. (2022). All the fish are not edible, therefore, visually recognizing the fish allows one to follow their movements, spot patterns and trends in their behaviors, and obtain a better understanding of the species as a whole (Rathi et al., 2017). It can be quite helpful for the policymakers. Fish behavior can be studied mechanically by gathering visual feedback from various locations and automating the classification of fish, which would result in a significantly larger amount of data for pattern recognition. Policymakers may facilitate modern fish farmers through growing technologies, such as the Internet of Things (IoT), big data, cloud computing, and Artificial Intelligence (AI), which can lead to sustainable farming (Iqbal et al., 2022).
Statement of the Problem
This study used Deep Learning (DL) to classify and identify fish. It may effectively advance the breeding industry's knowledge, monitor data on growth, promote the exchange of breeding expertise and experiences, stop breeding and sales losses brought on by information blockage, and increase the industry's value (Li et al., 2022). Since it is a multi-class classification problem, the recognition of fish species is a difficult field of research in machine learning and computer vision. The current study implemented contemporary algorithms that perform categorization mostly by recognizing and correlating the elements, such as shape and texture across distinct input pictures (Rathi et al., 2017). This is important as it would provide data about fish classification. This classification may be used both to identify endangered species and exportable genera since Pakistan has a long coastal line and such species can be exported to the Middle East, Europe, and the Americas.
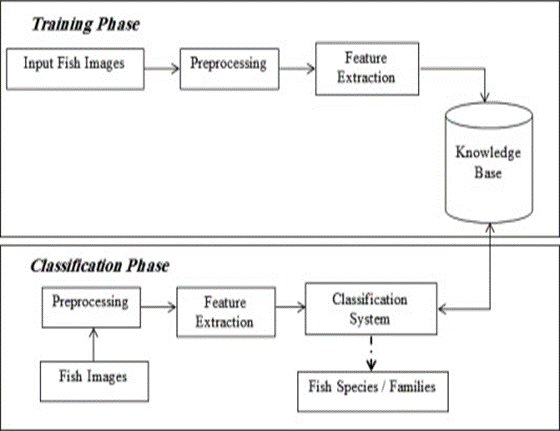
Figure 1
Fish Classification System (Kumar, 2023)
Objectives
The current study aimed to address the following objectives:
- Identification and classification of fish faces and species using the Convolutional Neural Networks (CNNs) model.
- The newest generation of DL algorithms, particularly CNNs, are widely used for species identification due to the growing demand for automated techniques to analyze underwater videos.
- To propose a predefined model that can perform more accurately.
- Use the studies to advise policymakers in order to formulate policies that may help in addressing endangered fish species extinction, enhancing fish breeds, and earning foreign exchange through the export of various fish breeds.
Research Questions
- Can CNNs be used to make the training and testing procedure easier and more reliable, even when working with a large dataset?
- Can policymakers use the results to address endangered fish species extinction, enhance fish breeds, and earn foreign exchange through the export of various fish breeds.
Significance
Fish species identification is crucial in managing fisheries and monitoring the environment. Fish species recognition is a challenging research area in machine learning and computer vision since it is a multi-class classification problem. Modern classification methods primarily employ shape and texture feature extraction and matching over individual input photos. All the previous studies are either inaccurate or deal with a small dataset that only distinguishes between a few species. CNNs streamline and strengthen the process even when dealing with big datasets. Additionally, CNNs are far more adaptable and may change to the new incoming data as the dataset develops. To test the approach used in the current study, the Fish4Knowledge project's fish dataset was used and by pre-processing the data, classification was carried out. (Rathi et al., 2017).
The study has a lot of significance as Pakistan has huge potential for seafood and fish products. Another significance of this research is that machine learning techniques are being used to address a critical policy area, which has a lot of beneficial potential for Pakistan in terms of fetching valuable foreign exchange. According to Mohsin et al. (2024) the country has a potential for seafood exports up to $1 Billion ("Pakistan's Seafood Exports", 2023).
Literature Review
This section identifies the existing work done in the area and related theories which cover this research theme. It includes related theories, opposing viewpoints in the literature, theoretical and conceptual framework, and literature gap. This section would lay the ground for the current research.
Related Theories
Fish are a crucial component of human culture, industry, and marine ecosystems. Globally, over 3 billion people consume fish per annum. Therefore, it is essential to monitor the frequency and quantity of fish species in order to inform conservation and governmental initiatives that guarantee healthy ecosystems and fish populations (Kandimalla et al., 2022). Amid the COVID-19 epidemic and the fourth industrial revolution, several simple and intermediate human jobs were replaced by computerized decision-making tools to enhance productivity while maintaining a social distance between workers and lower expenses. In a similar vein, the Internet of Things (IoT) is expanding rapidly and being used in a variety of fields to meet industrial needs and improve the quality of life. Resultantly, computer vision has replaced many manual inspection systems as an essential tool. In a study conducted by Anahita et al., they started with hyperspectral photos and progressed to nano images, such as satellite photographs (Khai et al., 2022). Smart fish farming is made possible by the automatic feature learning and high-volume modeling capabilities of DL, which also offers superior analytical tools for exposing, measuring, and interpreting vast volumes of information in big data. The issues of limited intelligence and subpar performance in the analysis of enormous, multisource, and heterogeneous big data in aquaculture can be resolved using DL approaches. It is possible to implement intelligent data processing and analysis, intelligent optimization, and decision-making control capabilities in smart fish farming by merging the IoT, cloud computing, and other technologies (Ji et al., 2023). In Harvey and Shortish, a successful method for real-time underwater fish identification was applied with stereo cameras and controlled lighting. To take pictures of fish, they were forced to swim through a designated chamber. Unrestricted underwater fish classification involves more challenging environments and difficult elements, such as varying lighting, water turbidity, background confusion caused by reef features and underwater plant life, and intra-species variation caused by shifts in the orientation of the freely moving fish. Digital cameras are typically used to record videos, and there is no presumption made about the underwater environment where the cameras are placed (Salman et al., 2016).
Existing Research in the Area
Fish can be classified based on their size, color, and shape. However, dependable species identification is difficult due to some species' similar shapes and patterns, low resolution and contrast, changes in light intensity, and fish movements (Alaba et al., 2022). Research on DL-based feeding choices has advanced significantly in recent years, therefore, precise fish behavior recognition can lead to optimal feed control, lower feeding expenses, and higher economic efficiency. Many researchers have studied fish behavior extensively with the aid of near-infrared imaging technology, a support vector machine (SVM), and a grey gradient symbiosis matrix (Iqbal et al., 2022). The distinguishing properties are implicitly extracted by DL-based vision algorithms, as opposed to the manually produced features that are typically employed in conventional ML techniques. A fish classification methodology built on a reliable feature selection method was described by Nery et al. The classifier employed the authors' proposed generic set of characteristics and their accompanying weights as prior knowledge to examine their effects on the entire classification task (Alaba et al., 2022; Carrington et al., 2021).
Theoretical and Conceptual Framework
The CNN model is used for the proposed framework, which is created to be sequential and produces a score for each class in a standard CNN-based multiclass classification problem. The query object's class is then determined by the score with the highest value. Resultantly, the CNN model treats each class equally. Some classes may be misclassified more frequently than others under this "flat" categorization structure, particularly those with fewer examples or those that are challenging to categorize due to similarities with other classes (Tamou et al., 2022a).
Figure 2
Overview of the Proposed System
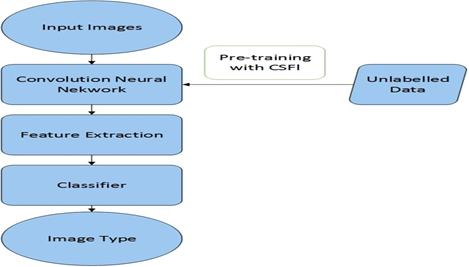
On the other hand, fish species are scientifically categorized according to taxonomy in biology. This hierarchical and biological classification places species in the same taxon when they share similar traits. By first placing species that share a taxon in the same subset for effective classification, a hierarchical categorization of fish species, based on CNN, is suggested.
Literature Gap
The current study aimed to classify and identify fish faces and species using the CNN model through DL. Currently, the use of DL-based algorithms are slowly gaining attention in animal research. The use of facial recognition technology with animals has some advantages. Firstly, animal facial recognition technology improves animal surveillance and protection. Secondly, facial recognition can aid in the wise management and breeding of animals. This can not only make digital management of farming easier, however, it may also help to prevent infections and improve farming organization, safety, and scientific rigor. Hence, a significant gap remains pertaining to the use of CNN and DL in assisting policymakers to devise policies with the aim to identify and classify fish species. Moreover, this classification may also be used to protect endangered species and export them to earn valuable foreign exchange.
Research Methodology
CNNs were developed from scratch in implementation of the proposed study technique. Six convolution layers, two pool layers, and two fully connected (FC) layers in model-1, and three FC layers in model-2 made up the CNN model. Without using the max-pooling function, CNN models were initially built in the experiment and observed throughout the testing stage. In the second stage of the experiment, both CNN models were subjected to the max-pooling function. The general architecture of both models is shown in Figure 3. The famine and normal stages of fish were quickly distinguished using the suggested framework. The Supplementary Materials section contains comprehensive details on model-1 and model-2's architecture including their convolutional layers, number of filters, kernel, and stride size.
Study Model
Computer scientists continue to choose CNNs for image recognition, processing, and classification. To achieve the desired accuracy when classifying images of various species and animals taken in dense forest environments, a fish image classifier was proposed using a CNN. This would help ecologists and researchers further understand and improve habitat, environmental, and extinction patterns. The training and development of a CNN allows for the accurate and efficient classification of these images.
Figure 3
Architecture of the Proposed Fish Identification and Classification Models
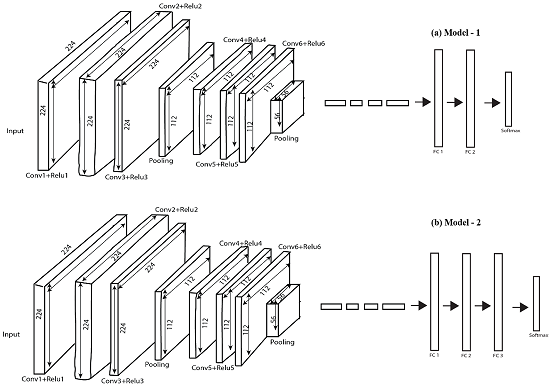
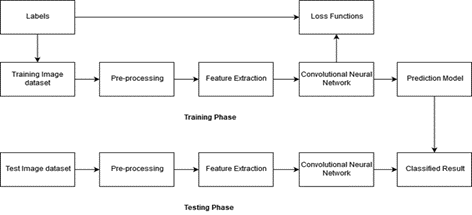
Figure 4
CNN Classification Flow chart
Data Collection Source /Availability
Data augmentation is used to slightly expand the dataset using a variety of techniques including color transformation, random rotation, rescaling, cropping, zooming, and contrast adjustments. There are numerous object detection and classification augmentation approaches. In the training dataset, we randomly crop, flip horizontally with a probability of 0.5, and add photometric distortion, such as random brightness change, random contrast, and random hue.
Population and Sampling
CNN models divided 100 photos into two groups in the suggested technique (normal and starvation). The dataset must be distributed evenly for both training and testing purposes. The learning rate adjustment during the training phase determines the maximum training accuracy and the lowest training loss. The training loss quickly decreased to a minimal level at the ideal learning rate. The
Figure 5
Dataset of 541 MB Taken from Kaggle

Proposed Tools and Software
MATLAB and Python are used to implement the proposed strategy. The proposed technique helps to make the neural network and generate computer vision. The dataset was collected by a reliable source. The method of training differs from traditional multi-class CNN training since it trains CNN simultaneously in each class. In the application, species are categorized based on how challenging they are. CNN is trained with the challenging species first and then incrementally taught to the other species.
Study Period
Convolutional layers, which are used to extract features from images, include several layers. An input layer, convolutional layers with nonlinear units, and fully linked layers are among the many layers that typically make up a CNN model.The first layer is the input layer which takes in image data from the outside world as learning resources. The size of the labeled underwater live fish datasets that are currently available is insufficient to train a CNN for fish species recognition from scratch. Additionally, enormous amounts of memory and processing power are needed (Tamou et al., 2022b).
Research Method
The dataset of different species of fish was taken from Kaggle and the size of the dataset was 541MB. AlexNet was used for the classification. Data was split into test data and train data. Seventy (70%) of the data was taken as train data and 30% was used as test data.
After the division of data into train and test, the features of train data were extracted. Features were extracted on three layers.
- Fc6
- Fc7
- Fc8
Fc8 is considered as a fully connected layer. The features of the initial layers are not as important as the features of the higher layers. After feature extraction, AlexNet was used to train the model. AlexNet is a CNN that is 8 layers deep (Tamou et al., 2022b). After training, different machine learning classification algorithms were used to find the best accuracy of classification.
The study used the following: Linear Discriminant Analysis, Naive Bayes, and Support Vector Machine
In the first analysis, machine learning algorithms were applied on each layer. Features were extracted on different layers, then on each layer NB, DA, and SVM were applied and accuracy was observed. Maximum accuracy was calculated on fc6 layers features. Afterwards, the fc6 and fc7 layers were concatenated as the dimensions on these two layers' output were the same, SVM, NB, and DA were applied on concatenated layers and efficiency was calculated.
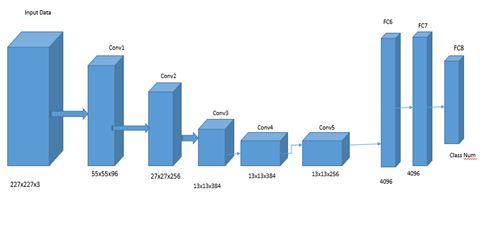
The architecture of AlexNet consists of 5 convolutional layers. The input is processed through these 5 convolutional layers, then features are extracted on the fc6, fc7, and fc8 layers.
Steps Involved in Feature Extraction
The steps involved in feature extraction are mentioned below:
A CNN with considerable success in image categorization is the AlexNet architecture. It has several layers including fully connected, pooling, and convolutional layers. These procedures can be used to extract features using AlexNet in MATLAB.
Load
- Preprocess the input image to meet AlexNet's requirements after loading it. Use the read function to read the input image. Imre size can be used to resize the image to the appropriate input size, which is often 227x227 pixels. There might also be a need to convert the image into single precision and subtract the mean image values.
- How to load the pre-trained AlexNet model in MATLAB: To load the pre-trained AlexNet model in MATLAB, use the AlexNet function. If the weights are not already available, this function would be downloaded automatically.
Command: net = AlexNet; Feature Extraction
Features can be extracted from a particular layer of the network using the activations function once the model has been loaded. High-level characteristics are often obtained from fully connected layer (fc7 in AlexNet) that comes before the classification layer.
layer = 'fc7';
features = activations (net, img, layer);
Use the Retrieved Features: The extracted features can be used for a variety of tasks including object detection, image classification, and further analysis. To classify images, for instance, the feature vector may be passed into a classifier.
The architecture of AlexNet is given below:
Figure 6
Architecture of AlexNet
ResNet50
Resnet is a CNN that is 50 layers deep (Tamou et al., 2022b). Resnet50 was used and features were extracted on 1000 layers. After feature extraction, SVM was applied and efficiency was calculated. Its efficiency was 0.50, therefore, other algorithms were not tried and 0.97 was already calculated from Alexie.
Results
Table 1 represents the efficiencies calculated using AlexNet and Resnet.
Table 1
Efficiencies of Different Classifiers
|
AlexNet |
|
|
Layer 6 |
|
|
ACCURACY 6 DA |
.9667 |
|
ACCURACY 6 NB |
.9667 |
|
ACCURACY 6 SVM |
.9671 |
|
Layer 7 |
|
|
ACCURACY 7 DA |
0.8667 |
|
ACCURACY 7NB |
.9 |
|
ACCURACY 7SVM |
.9 |
|
Layer 8 |
|
|
ACCURACY 8 DA |
0.8 |
|
ACCURACY 8 NB |
0.9 |
|
ACCURACY 8 SVM |
0.9333 |
|
FC6 and FC7, Layer Concatenation |
|
|
ACCURACY COMBINES FEATURES OF LAYERS FC6 & FC7 DA |
0.9333 |
|
DA: LINEAR DISCRIMINANT ANALYSIS NB: NAIVE BAYES SVM: SUPPORT VECTOR MACHINE |
|
|
RESNET50 |
|
|
SVM ACCURACY |
0.5 |
|
DA: LINEAR DISCRIMINANT ANALYSIS |
.78 |
Table 1 shows the efficiency values of different classification algorithms.
Figure 7
AlexNet Accuracy
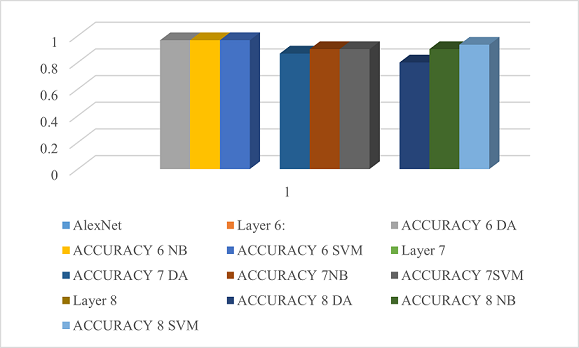
Figure 8
ResNet Accuracy
Figure 9
Comparison between ResNet and Alexnet
Confusion Matrix
With the aid of a confusion matrix, one may measure the AUC-ROC curve, recall, precision, and accuracy of machine learning techniques. To assign the predictions to the original classes to which the data originally belonged, confusion matrix is used (Ji et al., 2023).
- True Positive (TP): It indicates that a prognostication was made and then realized. It is occasionally described as sensitivity.
- True Negative (TN): It represents a bad omen which was predicted and subsequently came to pass. It is known as specificity.
- False Positive (FP): Although, the value was predicted to be positive, it turned out to be negative. Type-I errors are frequently used to describe it.
- False Negative (FN): Despite the negative projection, the actual number was positive. A Type-II mistake is another name for it.
The confusion matrix of the data and algorithms is given below:
Figure 10
Confusion Matrix
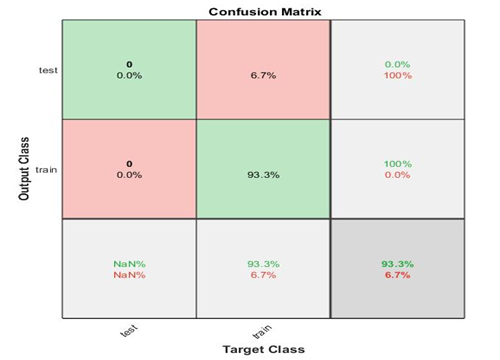
The following values can be calculated with the help of the confusion matrix:
- TPR
- TNP
- FPR
- FNR
Formulas of these values are given below:
Tpr = tp/(tp+fn) = 0% and 100%
Tnp = tn/(fp+tn) = 100% and 0%
Fpr = fp/(tp+fn) = NaN%
Fnr = fn/(fp+tn) = 93.3% and 6.7%
ROC Curve
Figure 11
ROC Curve (Accuracy 87.5)
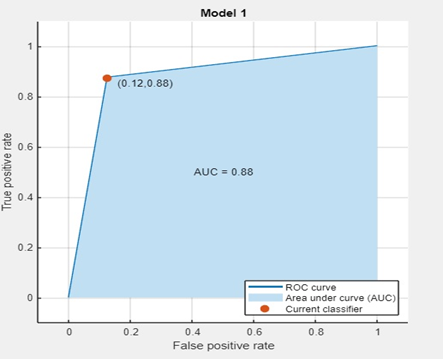
The trade-off between the true positive rate (TPR) and the false positive rate (FPR) at different categorization thresholds is visually represented by the ROC curve.
Following is a list of these terms:
The term "true positive rate" (TPR) can also refer to sensitivity or recall. TPR estimates the percentage of events that are correctly labeled as positive by the model (such as accurately detected cats).
False Positive Rate (FPR) is a measurement of the percentage of negative events that the model wrongly classifies as positive (e.g., grass mistaken for catla).
By generally adjusting the classification threshold of the model, the ROC curve depicts TPR on the y-axis and FPR on the x-axis. TPR and FPR are computed at various thresholds to create the curve. A different trade-off between TPR and FPR is represented by each point on the curve.
The location of the ROC curve represents the model's performance. As it symbolizes higher TPR and lower FPR, one wants the curve to be closer to the top-left corner. A model that performs well would have an ROC curve (a diagonal line extending from the bottom-left to the top-right) which is noticeably above the random baseline.
The model's overall performance across all conceivable classification thresholds can also be summarized using a scalar statistic known as the Area Under the ROC Curve (AUC-ROC). AUC-ROC values, which range from 0-1, reflect how well the classes can be distinguished.
By displaying a model's capacity to discriminate between several classes and offering a statistic that sums up its performance across various classification thresholds, the ROC curve and AUC-ROC are used to assess a model's classification performance including AlexNet.
This is because they consider all decision thresholds including irrational ones. The area under the receiver operating characteristic curve (AUC) and the area under the precision-recall curve are overly inclusive. On the other hand, the F1 score, sensitivity, specificity, positive predictive value, and accuracy are all calculated at a single threshold that is appropriate in certain circumstances but not in others, which is unfair. Deep ROC analysis is a better approach to use (Ji et al., 2023).
To calculate the performance of the model, two classes of fish were used, namely cattle and grass. Different classification models were applied and efficiencies were examined; the Roc curve was drawn to determine the efficiency of the model. With ROC, the efficiency of the tree-based model was observed to be 87.5, the efficiency of logistic regression was 81.2, whereas the efficiency of SVM was 100%.
Figure 12
ROC Curve
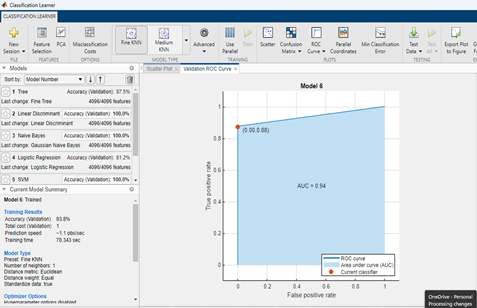
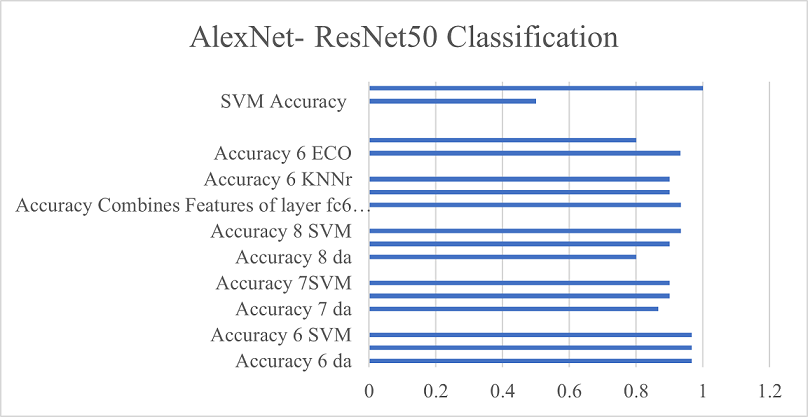
Figure 13
AlexNet Classification
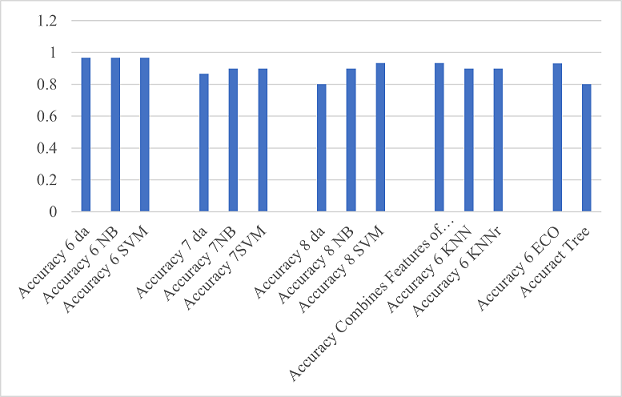
This graph shows the highest efficiency of SVM, DA, and NB on layer fc6 and combined fc6 and fc7 features.
Figure 14
Resnet Classification
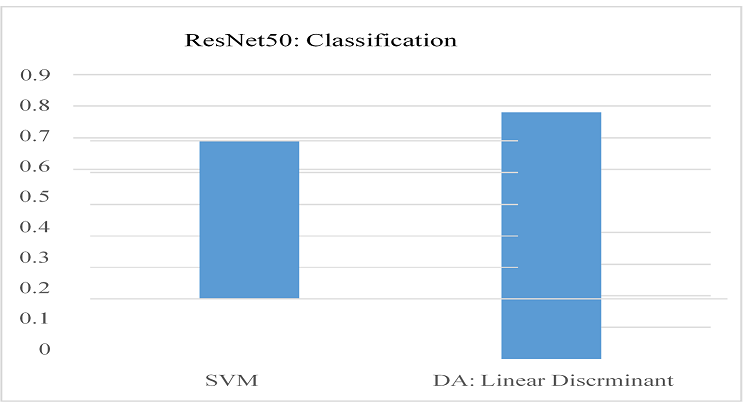
This graph shows ResNet's higher efficiency with a DA classification.
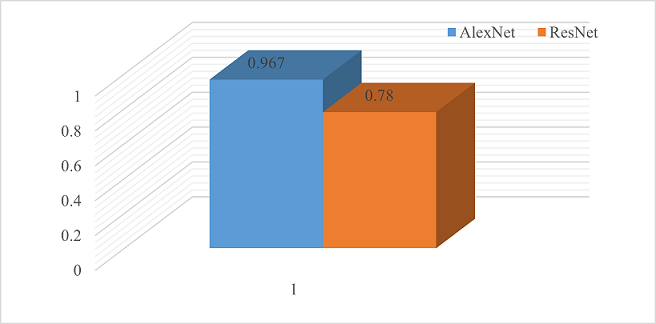
Figure 15
AlexNet and Resnet's Efficiencies
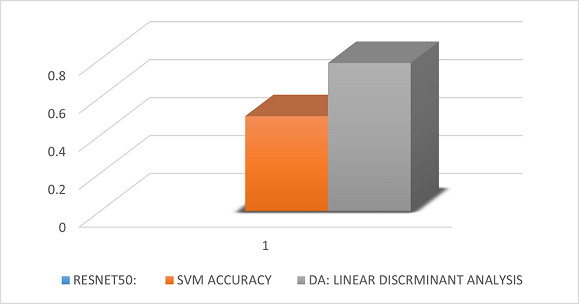
The following graph combines both AlexNet and Resnet's efficiencies.
Figure 16
Combined Graph of AlexNet and Resnet
Existing Fisheries Policy and Potential in Pakistan
Aquaculture is an industry with the fastest global growth. Moreover, aquaculture has also gained popularity in Pakistan in recent years and the government has since built a few fish hatcheries and training centers for fish farmers. Pakistan has the lowest level of fish aquaculture production among Asian nations, although the trend shows a sharp rise in aquaculture production.
Tilapia and pangasius are Pakistan's two main fish imports. Import duties on the two types of catfish include 20% customs duty, 35% regulatory duty, and 6% additional customs duty. Catfish is imported from Vietnam. Tilapia and Pangasius are aquaculture species that can be cultivated easily. Pakistan has recently begun cultivating Pangasius and Tilapia and the trials have shown continued success. Shrimps and prawns are the second largest exported category at HS-06, with frozen flat fish from demersal species of fish coming in the first place. Lack of storage space, improper fish handling techniques, noncompliance with SPS regulations, and the unavailability of contemporary processing equipment are some of the value chain barriers that impact the final product's quality.
COVID-19 pandemic has had a significant impact on the fishing industry. One of the main problems mentioned by exporters is the lack of containers which is a result of shipment delays brought on by China's and other nations' implementation of the COVID-19 regulations. According to exporters, problems with the supply chain and worldwide shortages have caused freight costs to rise by over 50%. In general, it is influencing exporters' profitability which is leading to a decrease in total exports. The European Union's ban on some fish species e.g. shrimps and prawns from Pakistan is another significant obstacle.
After a 100% laboratory test, only two exporters from Pakistan have been permitted by EU authorities to export fish, cuttlefish, and shrimp. Certain steps must be taken to resolve these problems. For instance, revisions are needed for chilling units, aquaculture, value-added processing, and quality control training, upgrading of sanitary controls in the fishing value chain, and fishing restrictions to prevent fish stock exhaustion (MathWorks, 2024b).
Discussion
The results mentioned above show that fish with export potential or those near extinction can be identified using machine learning and this allows policymakers to leverage these technologies to their advantage and generate significant foreign exchange earnings for Pakistan. Using AI approaches in the fish industry is a good approach for the industry. To promote a sustainable fishing sector, resource management is essential. Resource surveys in Japan depend on staff members taking measures by hand, which is expensive and restricts the number of practical measurements that can be made. This research aims to use image-recognition technology to transform resource surveys. Our approach entails creating a system that recognizes distinct fish regions in photos and automatically locates important keypoints for precise measurements of fish length. We employ a foundation paradigm for fish instance segmentation called grounded-segment-anything (Grounded-SAM). To precisely identify important fish keypoints, we also use a Mask Keypoint R-CNN trained on the fish image bank (FIB), an original dataset of fish images (Hasegawa & Nakano, 2024). This is a unique chance to employ AI to detect extinct fisheries and then create regulations for their best possible reproduction. AI is not often used in the Pakistani policymaking sphere. Over the years, Pakistan has experienced a sharp drop in the number of aquatic animals, particularly fisheries (Nusrat, 2021). The current study aimed to help policymakers identify and address fish shortages by utilizing AI, especially DL. Biologists and AI specialists can assist policymakers in achieving this task. While fish breeding still uses human identification techniques, aquaculture is one of several industries seeing a sharp rise in the application of DL technology. To gain a comprehensive understanding of fish behavior, marine biologists and ichthyologists need to possess an accurate taxonomy of fish species.
Studies shows a lot is work in progress in fish industry which is based on AI as Because of its nutritious value, tuna is a necessary fish and one of the most traded fish worldwide. The export industry manually separates these fish into different kinds. In order to fulfill the increasing demand for tuna and its products, this study suggests an automated method to expedite these industries. The study uses three different species of tuna. A pretrained U-Net model that has been fine-tuned on a bespoke dataset is first used to segment the fish images (Jose et al., 2022)
6.2 Conclusion
Automated fish type detection is a difficult undertaking, particularly near MHK and hydropower plants where the actual environment presents new challenges, such as light, turbidity, and high flow rates. Frame-wise fish type identification was contributed from three distinct small marine fish datasets, the majority of which contained coral fish species. Using the annotated datasets, the state-of-the-art object detection model YOLO was assessed. The findings demonstrated that the picture quality frequently restricts the detection accuracy, highlighting the necessity for higher-quality cameras for upcoming undersea energy projects to support the ecological assessment work. To identify objects in still photos including specific video frames, DL has achieved several remarkable accomplishments that have been documented in the literature. Benchmark datasets, such as COCO or ImageNet have been used extensively. Even though, these datasets offer a wide range of objects and image backgrounds, they are more akin to web images than they are to photographs taken for a real-world surveillance or monitoring project. Fish were the only object class of interest identified using the data used for this study. The utility of the pre-trained weights utilized in the current study is debatable since the COCO dataset lacks a fish object class. A model pre-trained on ImageNet may be more successful at identifying fish in these datasets since ImageNet features a fish class with multiple species-specific subclasses. The current study discovered that a model trained on two different datasets was ineffective at identifying fish in a completely new dataset due to variations in the video recordings including background, aspect angle of fish, size of fish, quality, and frame rate. The outcomes also demonstrated that when the third dataset was not included for training, the model performed better on two of the datasets. Several strategies were tested to increase the accuracy of underwater fish detection. The model might become more robust and generalized by using image augmentation techniques including cropping, flipping, rotating, and color shifting. Secondly, a group of detection models may perform better than a single model. Thirdly, to identify fish that appear hazy in the films, fish motion, which can be recovered from multi-frame ensembles, may be useful. This technique has been used to find tiny flying birds close to wind turbines (MathWorks, 2024a) and can be tried on recordings taken underwater. A 541Mb dataset was taken, containing different types of fish images. Both AlexNet and Resnet were used to classify the fish based on their different features. Different machine learning classification algorithms were used, for instance SVM, Naïve Bayes, and Linear Discriminate analysis. Fish industry is very important industry and with the help of AI we can improve the industry as according to a study the incorporation of echo signals into artificial intelligence algorithms represents a recent development in this field. Some of the most current and sophisticated methods that are utilized for automatic fish classification that helps fisherman locate the fishes are machine learning, deep learning, and fuzzy logic. To help fisherman save time by accurately detecting fish in the sea, this review paper focuses on the function of these sophisticated algorithms (Hadlee et al., 2023). Finally, to conclude, we state that artificial intelligence has been used to address the problem of ocean warming, an issue affecting the fishing sector globally as it can be used to predict sea temperatures, which can ultimately help in tracking fish and marine species movement and then using those to capture the fish for earning foreign exchange (Chen et al., 2023).
Conflict of Interest
The author of the manuscript has no financial or non-financial conflict of interest in the subject matter or materials discussed in this manuscript.
Data Availability Statement
The data associated with this study is openly available in Kaggle at [Kaggle: Your Machine Learning and Data Science Community], reference number [Kaggle. (2024, February 12). [Technology]. Level up with the Largest AI & ML Community. https://www.kaggle.com/].
Bibliography
- Alaba, S. Y., Nabi, M. M., Shah, C., Prior, J., Campbell, M. D., Wallace, F., Ball, J. E., & Moorhead, R. (2022). Class-Aware fish species recognition using deep learning for an imbalanced dataset.Sensors,22(21), Article e8268. https://doi.org/10.3390/s22218268
- Carrington, A. M., Manuel, D. G., Fieguth, P. W., Ramsay, T., Osmani, V., Wernly, B., Bennett, C., Hawken, S., McInnes, M., Magwood, O., Sheikh, Y., & Holzinger, A. (2021). Deep ROC analysis and AUC as balanced average accuracy to improve model selection, understanding and interpretation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(1), 329–341. https://doi.org/10.1109/TPAMI.2022.3145392
- Chen, L., Hua, H., Luo, X., Xu, G., & Yan, X. (2024). Prediction of the Economic Behavior of Fishery Biotechnology Companies Based on Machine Learning-Based Deep Metacellular Automata.arXiv preprint arXiv:2402.13509.
- Hadlee, R. R., Gudadhe, A. A., Kumar, J. P., Puri, C. G., & Verma, P. (2023, November). An Analysis of Training Artificial Intelligence Techniques into Eco Sounder Machine to Identify Fish. In2023 1st DMIHER International Conference on Artificial Intelligence in Education and Industry 4.0 (IDICAIEI)(Vol. 1, pp. 1-5). IEEE.
- Hasegawa, T., & Nakano, D. (2024). Robust Fish Recognition Using Foundation Models toward Automatic Fish Resource Management.Journal of Marine Science and Engineering,12(3), 488.
- Iqbal, U., Li, D., & Akhter, M. (2022). Intelligent diagnosis of fish behavior using deep learning method.Fishes,7(4), Article e201. https://doi.org/10.3390/fishes7040201
- Ji, W., Peng, J., Xu, B., & Zhang, T. (2023). Real-time detection of underwater river crab based on multi-scale pyramid fusion image enhancement and MobileCenterNet model.Computers and Electronics in Agriculture,204, Article e107522. https://doi.org/10.1016/j.compag.2022.107522
- Jose, J. A., Kumar, C. S., & Sureshkumar, S. (2022, February). Automated region split algorithm with pre-trained CNN model for tuna classification. In 2022 First International Conference on Electrical, Electronics, Information and Communication Technologies (ICEEICT) (pp. 1-5). IEEE. https://doi.org/10.1109/ICEEICT53079.2022.9768589
- Kandimalla, V., Richard, M., Smith, F., Quirion, J., Torgo, L., & Whidden, C. (2022). Automated detection, classification and counting of fish in fish passages with deep learning. Frontiers in Marine Science, 8, Article e823173. https://doi.org/10.3389/fmars.2021.823173
- Khai, T. H., Abdullah, S. N. H. S., Hasan, M. K., & Tarmizi, A. (2022). Underwater fish detection and counting using mask regional convolutional neural network. Water, 14(2), Article e222. https://doi.org/10.3390/w14020222
- Kumar, A. (2023, December 4). Different types of CNN architectures explained: Examples. Analytics Yogi. https://vitalflux.com/different-types-of-cnn-architectures-explained-examples/
- Li, D., Su, H., Jiang, K., Liu, D., & Duan, X. (2022). Fish face identification based on rotated object detection: Dataset and exploration. Fishes, 7(5), Article e219. https://doi.org/10.3390/fishes7050219
- MathWorks. (2024a). Deep Learning Toolbox: Design, train, analyze, and simulate deep learning networks. https://www.mathworks.com/help/deeplearning/ref/alexnet.html
- MathWorks. (2024b). Resnet50: ResNet-50 convolutional neural network. https://www.mathworks.com/help/deeplearning/ref/resnet50.html
- Mohsin, M., Yin, H., & Mehak, A. (2024). Sustainable solutions: Exploring risks and strategies in Pakistan's seafood trade for marine conservation.Frontiers in Marine Science,11, Article e1420755. https://doi.org/10.3389/fmars.2024.1420755
- Nusrat, S. (2021). Fisheries: Potential of Pakistan. Trade Development Authority Pakistan. https://tdap.gov.pk/wp-content/uploads/2022/03/Fisheries-Potential-of-Pakistan-Salma-Nusrat.pdf
- Pakistan's seafood exports have massive growth potential (2023, August 31). The Nation. https://www.nation.com.pk/31-Aug-2023/pakistan-s-seafood-exports-have-massive-growth-potential
- Rathi, D., Jain, S., & Indu, S. (2017, December 27–30). Underwater fish species classification using convolutional neural network and deep learning [Paper presentation]. InProceedings of 2017 9th international conference on advances in pattern recognition. Bangalore, India.
- Salman, A., Jalal, A., Shafait, F., Mian, A., Shortis, M., Seager, J., & Harvey, E. (2016). Fish species classification in unconstrained underwater environments based on deep learning.Limnology and Oceanography: Methods,14(9), 570–585. https://doi.org/10.1002/lom3.10113
- Tamou, A. B., Benzinou, A., & Nasreddine, K. (2022a). Live fish species classification in underwater images by using convolutional neural networks based on incremental learning with knowledge distillation loss.Machine Learning and Knowledge Extraction,4(3), 753–767. https://doi.org/10.3390/make4030036
- Tamou, A. B., Benzinou, A., & Nasreddine, K. (2022b). Targeted data augmentation and hierarchical classification with deep learning for fish species identification in underwater images.Journal of Imaging,8(8), Article e214. https://doi.org/10.3390/jimaging8080214