An Acoustic Analysis of Vowel Nasalization in Pakistani English
Maryah Khalfan* and Uzma Abid
Air University Islamabad
Abstract
Nasalization is allophonic in English but phonemic in many Pakistani languages. This has contributed to different degrees of nasalization in Pakistani English (PakE) vowels in nasal context as compared to British English (BE) vowels. The current study aims to acoustically investigate vowel nasalization in PakE using the parameters of A1-P1 and spectral flattening in a sample of PakE speakers with six different L1s, Sindhi, Punjabi, Pashto, Baluchi, Shina, and Urdu, to show similarities and differences with BE. A higher degree of nasalization was observed in CVN and NVN contexts throughout PakE speakers, regardless of L1, as compared to BE sample where nasalization was altogether absent in NVC context. While BE speakers nasalize vowels regressively, PakE speakers nasalize regressively and progressively.
1. INTRODUCTION
English is an official language of Pakistan; though not a native language, it has been nativized over the passage of time. Used extensively in local and national settings, in administrative, bureaucratic, business and higher education domains, it has become the key to accessing the corridors of power in Pakistan. Due to the influence of local culture and languages over 200 years, the variety of English spoken in Pakistan has undergone many systematic changes which have given it a flavor distinct from the British English (BE) it evolved from. Pakistani English (PakE) has its own phonological, lexical, morphological, and syntactical features, wherein it differs from standard BE and other World Englishes (Baumgardner, 1995; Mahboob & Ahmer, 1994; Rahman, 1990; Raza, 2008). Previous studies have established the distinct phonological, morphological, syntactical, and semantical presence of PakE; however, in the phonological field, there are hardly any studies on nasalization in PakE so far. The phenomenon has been discussed briefly and perceptually in some studies (Mahmood et al., 2011; Rahman, 1990; Rehman, 2019); however, it has only been acoustically investigated in one study conducted by Zahid and Hussain (2012). The study investigated vowel nasalization in Punjabi speakers' production of English using acoustic parameters of A1 – P0 and A1 – P1 and found that Punjabi speakers of English strongly nasalized vowels in regressive nasalization or VN context. This is the only study that has empirically investigated vowel nasalization in a single L1 group of PakE speakers using authentic and viable acoustic correlates for the purpose. However, vowel nasalization was studied in L1 Punjabi speakers only which cannot be generalized for PakE speakers. The current study has extended the sample to investigate vowel nasalization in speakers of six major languages of Pakistan.
An important aspect of PakE is that it is heterogeneous due to the different first languages spoken by Pakistanis. The influence of L1 phonology on L2 acquisition has been established by many studies (Major, 1987; McAllister et al., 2002; Zhanming, 2014; Zobl, 1980), thus it would be pertinent to investigate how different L1s spoken in Pakistan influence the English acquired by Pakistani speakers. The current study has included a sample that represents speakers from all provinces of Pakistan (Punjab, Sindh, Baluchistan, Khyber Pakhtunkhwa, and Gilgit Baltistan) along with the Urdu-speaking community to account for similarities and differences within PakE based on a comparison of recordings of speakers with different L1s.
Research Problem
Research on nasalization of vowels in PakE has been restricted by studies employing delimited samples of single L1, L1-independent samples, and a traditional methodology based on perception and intuition (Rahman, 1990; Hassan, 2016; Saleem et al., 2002; Singh & Lehal, 2010). With the advent of modern speech analysis software, there is no reason to procure findings based on subjective auditory perception. The current study has used PRAAT software to acoustically analyze nasalization in PakE spoken by university students with varying L1s to contribute empirically to the phonological system of PakE.
Research Questions
The current study attempted to provide empirical evidence of vowel nasalization in PakE. It entailed the presentation of differences between PakE and BE vowels in nasal contexts and also similarities within the speakers of various Pakistani regional languages in the same contexts. The objective of the study was pursued through the following research questions:
- How does vowel nasalization in PakE present in acoustic analysis?
- How do PakE acoustic presentations differ from a native BE speaker's presentation?
- Is vowel nasalization uniformly present in Pakistani university students with different L1s?
Literature Review
Assimilation refers to the process wherein a sound becomes similar to a sound in its immediate vicinity. Nasalization is a common type of assimilation where a sound normally produced orally is articulated through the nasal cavity due its proximity to a nasal phoneme (Archibald, 1998; Beddor, 1993; Kluge et al., 2008). Nasalization occurs in almost all languages of the world (Kluge et al., 2008), however, the degree of nasalization differs from language to language and from person to person. Ladefoged and Disner (2012) have explained the process of contextual nasalization in feature theory as the feature of [+nasal] of a nasal consonant being extended to the vowel preceding or succeeding it. Thus, the feature [+nasal] is now a feature of the vowel as well.
[+vowel] [+nasal] [+vowel+nasal] [+nasal] = regressive nasalization
[+nasal] [+vowel] [+nasal] [+vowel+nasal] = progressive nasalization
English has contextual nasalization where vowels are nasalized when they occur in a VN context. Longer vowels are more prone to be nasalized than short vowels in some languages (Whalen & Beddor, 1989), whereas lower vowels are more nasalized than higher vowels (Bell-Berti, 1993). In English, nasalization is mostly regressive; it occurs more often in the VN context than in the NV context. Pakistani languages have contrastive nasalization, more commonly regressive than progressive (Hassan, 2016; Saleem et al., 2002; Singh & Lehal, 2010; Wali, 2003).
Many studies have investigated the acoustic parameters that can be used to identify and measure nasalization. It is a difficult phenomenon to examine and generalize findings due to immense variation in the anatomy of the nasal cavity, the degree of distribution of air between oral and nasal cavity during articulation. These variables differ from speaker to speaker, so it is quite difficult to find acoustic measures that may be generalized across languages (Ladefoged & Maddieson, 2001; Pruthi & Espy-Wilson, 2007). However, over the last few years, researchers have devised certain acoustic cues to observe nasalization in spectrograms and LPCs/FFTs. Increased vowel duration is considered an acoustic indicator of nasalization (Cagliari, 1977; Whalen & Beddor, 1989). Maeda (1982) investigated nasalization in 11 French vowels and found that there was significant flattening in the spectra between 300-2500Hz due to the effect of coupling of nasal and oral cavities. Spectral flattening refers to an area on the spectrogram which is low in energy and valleys between formants are blurred and hazy. The study suggested spectral flattening to be the foremost cue for nasalization. An increase in F1 frequency has also been touted as an acoustic cue of nasality, as a nasal formant forms above (in case of high vowels) or below (in case of low vowels) the F1. This nasal formant increases the frequency of F1 (Fujimura & Lindqvist, 1971; Kluender et al., 1988). Researchers have focused on the decrease in amplitude of F1 as an indication of nasalization (Chen, 1997; House & Stevens, 1956; Ladefoged & Maddieson, 2001). The range of amplitude lowering is disputed amongst researchers; House and Stevens (1956) held that a 6-7db decrease was an acoustic cue of nasality, while Chen (1997) argued that the range differed from speaker to speaker.
Vowel nasalization has received very little attention from PakE researchers with only one study investigating vowel nasalization in Punjabi speakers (Zahid & Hussain, 2012). The limited sample of the study in terms of single L1 (five Punjabi speakers) restricts the study from claiming findings for all PakE speakers. The current study filled this gap by using a larger sample accommodative of all major regional languages of Pakistan.
Methodology
The current study is descriptive in nature employing phonetic data analysis techniques, primarily consisting of acoustic analysis of recordings on PRAAT software. PRAAT analysis was followed by a summary narrative to explain the results of the analysis. To investigate nasalization, acoustic parameters of A1–P1 and spectral flattening were employed. In the parameter A1–P1, A1 is the amplitude of F1 of the vowel and is calculated as the highest harmonic peak between 300-900Hz. P1 is the amplitude of the highest harmonic peak near the nasal formant at around 950Hz between F1 and F2 (Chen, 1997; Chen et al., 2007). According to Fujimura and Lindqvist (1971), in the case of nasalization, A1 would decrease as coupling with nasal cavity would reduce energy in oral cavity. On the other hand, P1 would increase with the introduction of nasal formant, so the difference between A1 and P1 (A1 - P1) would be less for nasalized vowels. Maeda (1981)'s model of spectral flattening as a cue of nasalization was also used in the current study. As the nasal cavity couples with the oral cavity, energy is distributed between the two cavities resulting in less energy manifesting on the spectrogram in the areas showing vocal tract energy (F1 and F2). This area on the spectrogram becomes light in color showing little or no energy and undefined formants.
The population of the study comprised all university students speaking PakE with L1 Urdu, Punjabi, Sindhi, Balochi, Pashto, and Shina. These are the main languages spoken in Pakistan, covering over 80% of the population according to 2017 census[1]. Purposive sampling was used to select a sample of 30 participants from Air University, Islamabad, and Quaid-i-Azam University, Islamabad. The 30 participants included five speakers each of L1 Urdu, Punjabi, Pashto, Sindhi, Balochi, and Shina. Speakers with six different L1s were chosen to increase the external validity of the study to apply to all PakE-speaking university students. Participants were debriefed regarding the protection of their privacy and confidentiality measures, wherein each participant was assigned a number attached to L1: P1-5 Sindhi for Sindhi speakers, P1-5 Punjabi for Punjabi speakers, and so on.
The purpose of the study was to provide empirical evidence of vowel nasalization in PakE by investigating nasalization in three different contexts: CVN, NVC and NVN with high front vowel /iː/ in all contexts (Chen et al., 2007). Three words containing the stimuli (mean, meet and team) at three different contexts were chosen to investigate nasalization and arranged in a sentence frame ‘I mean we are a team when you meet'. The rationale for choosing one-syllable word with the long high front vowel /iː/ at the nucleus was that previous studies had found it to be an opportune context to investigate nasalization (Chen 1997; Chen et al., 2007). Vowel nasalization is more prominent in vowels of longer duration and F1 and F2 formants are more distinguishable from nasal formants in high vowels (Chen et al., 2007).
In a controlled reading task, participants were briefed to read the frames from the sheet five times each in natural accent without contrivance. This gave 30 * 5 * 5 = 750 utterances. The purpose of recording utterances of connected speech was to minimize deliberate change in articulation. The utterances were recorded with an external microphone SONY Headset HS-75 attached to a laptop. The utterances by a native BE speaker were taken from Creative Commons files on the Internet. The files were then analyzed on PRAAT software to compare the utterances of PakE speakers with each other and with a native BE speaker.
The recordings of stimuli were viewed on PRAAT on narrow band spectrogram set at 0.025 window length and Hamming window shape. The vowel was selected in zoom window and its onset, mid, and end points were selected from the window. Formants were obtained for each point and F1 and F2 were noted down to assist later in locating A1 and P1 in spectral slice. A spectral slice of each vowel point was opened and zoomed to show the range of 0-5000Hz. The slice showed amplitude in decibels on the x-axis and frequency on the y-axis. Two cues were used to locate A1:
- The highest peak near the F1frequency already noted from spectrogram
- The highest peak between 300-900Hz
Three cues were observed to locate P1:
- The highest peak between 770-1500Hz
- The highest peak near 950Hz
- The high peak between F1 and F2 as noted from spectrogram
After ascertaining A1 and P1, a screenshot was taken of the slice and marked with 2 horizontal red lines depicting the amplitude of the peaks in dBs. A1 and P1 were also marked on top of the peaks in red and A1 – P1 difference was marked with a vertical blue line. Mean A1 – P1 was taken by adding the three values obtained from three different points of vowel. A range of mean A1 – P1 of vowels of PakE speakers for each context was calculated and compared to BE vowels' A1 – P1 to investigate in which context PakE speakers nasalize vowel and to what degree. A1 – P1 of a BE and PakE oral vowel was also calculated with the same vowel /i:/ in CVC context to provide a standard to measure nasalization against.
To investigate spectral flattening, spectrograms of BE and PakE recordings were segmented, glossed, and transcribed on text grids and a horizontal red dotted line was used to mark the upper boundary of 2500Hz. In case of spectral flattening, a band of low energy starting from the top of the nasal formant (below 300Hz) extends to the red dotted line of 2500Hz. After ascertaining acoustic cues and parameters for identifying and measuring each variable and sub-variable, the concerned segments were analyzed acoustically on PRAAT.
Analysis
Vowel Nasalization in NVC Context
The most significant difference in nasalization was observed in the context of NVC, as progressive nasalization was absent in BE. Spectral slice analysis of vowels at three places in BE recording showed A1 – P1 of 29dB, 29.9dB, and 34dB respectively. Readings at three points of vowel reflected similar A1 – P1 showing that the context of nasal consonant at onset position does not affect vowel. Mean A1 – P1 of three points of vowel was 31.3dB showing there was no nasalization in BE recording in NVC context. PakE spectral slice analysis of vowels gave a range of A1 – P1 between 16 and 22dB showing a difference of at least 9dB with BE recording. This difference reflects the presence of nasalization in PakE renditions of NVC stimulus, albeit low in degree.
Figure 1
Spectral Slice of Vowel in BE Recording /miːt/

Spectral slice of BE vowel has been taken at midpoint with F1 = 237Hz. A1 is amplitude of highest peak near 237Hz and P1 is amplitude of highest peak near 950Hz. A1 – P1 = 45.5dB – 15.9dB = 29.9dB. Mean A1 – P1 for readings of vowel at three points was (29 + 29.9 + 34) /3 = 31.3dB.
Figure 2
Spectral Slice of Vowel in PakE Recording /miːt/ (1)

The spectral slice has been taken at midpoint vowel in /miːt/ spoken by P2 Sindhi. The F1 has been pushed to a higher frequency (F1 = 475Hz) due to the introduction of nasal formant at around 250Hz, resultantly A1 has moved forward. A1 has been calculated as highest peak between 300-900Hz, specifically near 470Hz. P1 is highest peak around 950Hz. A1 – P1 at midpoint of vowel was 29dB – 8.8dB = 20.2dB. Mean A1 – P1 for three points of vowel was (16.5 + 20.2 + 23.3)/3 = 20dB. It may be noted that A1 – P1 was lowest at initial reading of vowel (16.5) showing the highest degree of nasalization at onset of vowel. This reflects the contextual influence of nasal consonant at onset position.
Vowel Nasalization in NVN Context
In case of NVN context where coda nasal was /n/, nasalization was observed in both BE and PakE recordings; however, PakE speakers nasalized vowel to a higher degree than BE.
Figure 3
Spectral Slice of Vowel in BE Recording of /miːn/
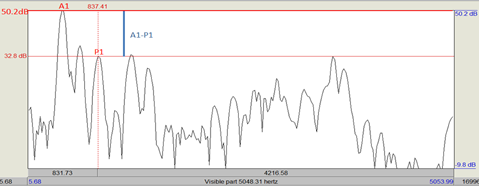
The spectral slice shows mid vowel point of /iː/. A1 is the highest peak between 300-900Hz close to F1 445Hz and P1 is the highest peak between 770-1500Hz near the nasal formant 950Hz. A1 – P1 at midpoint vowel was 50.2 – 32.8 = 17.4dB. Taking mean A1 – P1 from all three points of vowel gives (18 + 17.4 + 11.4) /3= 15.6dB. This is definitely a higher degree of nasalization for BE than in NVC context discussed above (29.9dB). PakE speakers' recordings also showed a high degree of nasalization, higher than BE recordings and higher than PakE recordings in other contextual environments NVC and CVN. The range of mean A1 – P1 for all participants was between 5 and 10dB, significantly less than all other readings.
Figure 4
Spectral Slice of Vowel in PakE Recordings of /miːn/

The spectral slice was taken from mid vowel point of /iː/ from an L1 Shina speaker. The A1 is the highest harmonic peak near F1 350Hz and P1 is the highest peak near 950Hz. A1 – P1 at this point of vowel is 31.8 – 23.6 = 8.3dB. Mean A1 – P1 for three points of vowel was (8.4 + 8.3 + 6.3) /3 = 7.6dB. A1 – P1 was lower at end point of vowel showing more nasalization at the end of vowel, closer to the coda nasal /n/.
In conclusion, BE speaker and participants all nasalized vowels in NVN context; however, all participants exhibited a greater degree of nasalization (frequency = 100%). Some recordings showed a trend of higher nasalization at onset point of vowel, while others showed vowel was nasalized more at its end point.
Vowel Nasalization in CVN Context
In case of CVN context where coda nasal consonant was /m/, less degree of nasalization was observed in both BE and PakE recordings with BE recording having slightly less or similar degree of nasalization as PakE recordings.
Figure 5
Spectral Slice of BE Recording of /tiːm/

Spectral slice has been taken at midpoint of vowel in /tiːm/. A1 (42dB) is the highest amplitude between 300 – 900Hz close to 584Hz. P1 (15.6dB) is amplitude of the highest peak near the nasal formant at 950Hz. A1 – P1 at midpoint of vowel was 42 – 15.6 = 26.4dB. Mean A1-P1 was calculated as (17.5 + 26 + 22.9) /3 = 22.1dB. The high A1-P1 indicates less nasalization even though regressive nasalization is common in BE. This indication of low degree of nasalization may be attributed to the fact that nasal /m/ induces less vocalic nasalization then /n/ (Bell-Berti, 1993).
Figure 6
Spectral Slices of PakE Recordings of /tiːm/
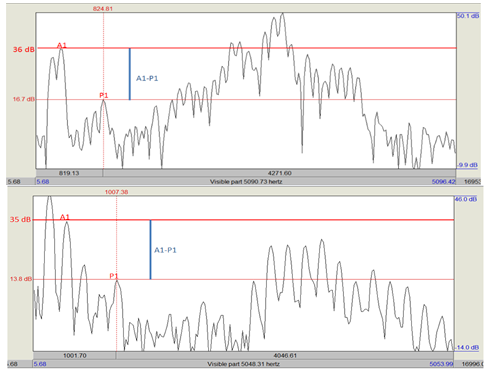
Note. Top to bottom: P4 Pashto and P2 Punjabi.
The first slice shows A1 – P1 of 36 – 16.7 = 19.3dB. Mean A1 – P1 for all three points of vowel was (19 + 19.3 + 16) /3 = 18.3dB. In the lower slice, A1 – P1 at midpoint of vowel was 21.2Db, whereas mean A1 – P1 for three points of vowel was (24.3 + 22 + 15) /3 = 20.4dB. A similar to lower A1 – P1 was observed in participants' recordings. Range of mean A1 – P1 of three readings per vowel fell between 16dB-22dB. Thus, PakE speakers also nasalize vowels less in VN context where N is /m/ than in VN where N is /n/.
Spectral Flattening
Another acoustic parameter of nasalization is spectral flattening between 300-2500Hz (Maeda, 1982). Spectral flattening at low frequencies, specifically between 300-2500Hz, has been considered a significant indicator of nasalization (Maeda, 1982; Pruthi & Espy-Wilson, 2007). As the nasal cavity couples with the oral cavity, energy is divided between the two cavities resulting in less energy in the oral cavity. Resultantly, the spectrogram shows less energy in the areas showing vocal tract energy (F1 and F2). This area on the spectrogram becomes light in color showing little or no energy and undefined formants. The following spectrograms of BE and participants' recordings offer a visual comparison of the acoustic cue of spectral flattening.
Figure 7
Spectrograms of Stimulus in NVC Context

Note. Clockwise from Top: BE, P4 Sindhi and P1 Urdu.
The BE spectrogram shows no spectral flattening; the nasal /m/ transitions into the vowel which has visible formants and dark energy. The vowel energy tapers off as vowel transitions into stop /t/. On the contrary, the participants' spectrograms show that the spectrum has been flattened between 300Hz and 2500Hz marked by the red dotted line. The energy band below 300Hz denotes the nasal formant which is the only formant visible until 2500Hz. All participants nasalized the vowel in NVC context (frequency = 100%) showing progressive or carryover nasalization which is absent in BE recording.
Figure 8
Spectrograms of Stimulus in NVN Context
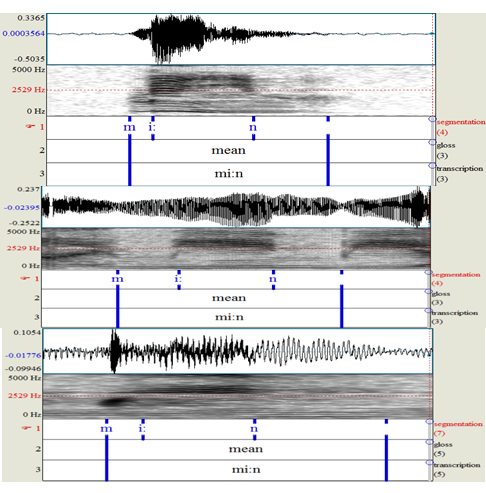
Note. Clockwise from top: BE, P3 Shina and P1 Balochi.
The BE spectrogram shows energy below the dotted red line of 2500Hz; however, the energy becomes lighter towards the latter part of the vowel showing regressive nasalization from the coda nasal /n/. Participants' spectrograms show evident spectral flattening from the beginning of the vowel to its end denoting clear nasalization of the complete vowel.
Figure 9
Spectrograms of Stimulus in CVN Context
Note. Clockwise from top: BE, P4 Punjabi and P4 Pashto.
The BE spectrogram shows clear formants and dark energy below the 2500Hz red dotted line, especially at vowel onset. Spectral flattening between 300-2500Hz is visible after midpoint of the vowel as it transitions towards the following nasal /m/. Participants' recordings clearly show very low energy below the 2500Hz line in both spectrograms throughout vowel production. The flattening starts after the release of /t/ and remains the same till transition of vowel to nasal. Thus, in participants' recordings, nasalization began as soon as the vowel started in CVN context, while BE recording showed that vowel became nasalized closer to the nasal.
Discussion
Acoustic parameter A1 – P1 showed vowel nasalization in PakE was higher in NVC and NVN context, whereas there was a similarly moderate degree of nasalization in PakE and BE in CVN context. The acoustic cue of spectral flattening from 300Hz to 2500Hz provided graphic evidence of regressive nasalization in BE recordings which confirmed the findings of studies on English nasalization (Bell-Berti, 1993; Whalen & Beddor, 1989), while PakE participants nasalized vowels in all contexts of nasal environments, be it CVN, NVN or NVC. All participants exhibited both regressive and progressive nasalization. Pakistani regional languages have contrastive nasalization; however, this does not preclude contextual nasalization in both VN and NV contexts (Zahid & Hussain, 2012). The presence of vowel nasalization in all contexts in PakE recordings may be due to the linguistic factor that all vowels in Pakistani regional languages can be nasalized, as nasalization is phonemic. The L1 propensity to nasalize vowels is carried on into L2, and wherever a nasal context is present, speakers nasalize vowels as they would in L1. All PakE speakers nasalized vowels in NVC and NVN context more than BE speaker, however, in CVN context, nasalization of a similar degree was observed in BE and PakE speakers.
Table 1
Vowel Nasalization in PakE
|
Vowel Nasalization |
Frequency of Difference of PakE speakers with BE |
Frequency of Difference within PakE speakers |
Findings |
|
NVC context |
100% PakE vowel was nasalized, BE vowel non nasalized |
0% Low to medium nasalization between 16-22dB |
All PakE speakers nasalize vowels moderately in NCV context |
|
NVN context |
100% PakE vowels had higher degree of nasalization |
0% High nasalization between 5-10dB |
All PakE speakers nasalize vowels significantly in NVN context |
|
CVN context |
0% PakE and BE vowels had same degree of nasalization |
0% Low to medium nasalization between 16-22dB |
All PakE speakers nasalize vowels moderately in CVN context |
The current study confirmed Zahid and Hussain's (2012) finding that Punjabi speakers produced high degree of regressive nasalization. However, the study also determined that nasalization was highest in NVN context, while regressive nasalization in CVN context was less and quite similar for PakE and BE recordings. PakE speakers also exhibited progressive nasalization in NVC context. Perception-based studies (Hassan, 2016; Saleem et al., 2002; Singh & Lehal, 2010) claimed the absence of progressive nasalization in Pakistani languages; however, Zahid and Hussain (2012) found progressive nasalization in PakE speakers with L1 Punjabi. This can perhaps be attributed to the higher sound sensitivity and precision afforded by speech software as compared to the subjective auditory perception of speech.
Conclusion
The current study attempted to investigate vowel nasalization in PakE by comparing acoustic presentations of PakE speakers with a BE speaker. A quantitative methodology was adopted wherein two acoustic parameters were used to analyze vowel production in nasal contexts. The key findings of the study in context of the research questions are as follows:
- Acoustic presentations of recordings of Pakistani university students with different L1s showed that they unanimously nasalized vowels in nasal contexts.
- While regressive nasalization was most pronounced, progressive nasalization was also present to a moderate degree.
- PakE differs from BE in this regard, as BE recording showed regressive nasalization only.
The investigation of vowel nasalization is both a complex and composite research which has been neglected in PakE. This may be attributed to the relatively difficult and intricate procedures and calculations requisite to the investigation. However, vowels and the way they behave in different contexts is pivotal to an understanding of the phonology of a language. The current study is unique in investigating vowel nasalization in PakE speakers having six different L1s, and carries pedagogical implications for language teaching and learning. By contributing to a comprehensive record of the phonological system of PakE in text books and curricula, this study offers a framework for teachers to teach English with the prior knowledge of what constitutes error in pronunciation and what is expected based on Pakistani nativization of English. The study also provides a resource for speech recognition and voice command software in functions such as speech-to-text, automated transcription, etc. Saving waves containing phonological differences and characteristics of PakE in such software would allow computers to recognize speech patterns and in turn, they would be able to transcribe and obey commands. The inclusion of PakE speech patterns would greatly convenience PakE speakers in using Dictaphone products, voice recorder technology, transcription services, and virtual assistant software.
The current study also has implications for speech therapy, particularly in terms of articulation disorders. An acoustic record of the characteristics of PakE phonology which differ from BE phonology would greatly assist speech therapists in identifying and extricating phonological gestures from phonological errors in spectrograms of patients, thereby clearly delineating areas that require therapy and those that do not.
This study is limited by the use of two acoustic parameters in its investigation of vowel nasalization in PakE speakers due to time and capacity restraints. A complete study on vowel nasalization in PakE is recommended with a methodology that includes data analysis methods pertaining to parameters in addition to the ones used in this research. These additional parameters may include A1 – P0, F1BW, and nPeaks40dB to allow a comprehensive comparison of results from different parameters to increase internal validity. This would be particularly rewarding in case of PakE since there is a dearth of research on vowel nasalization.
[1] https://www.statista.com/statistics/991828/pakistan-population-by-language/
Conflict of Interest
The author of the manuscript has no financial or non-financial conflict of interest in the subject matter or materials discussed in this manuscript.
Data Availability Statement
The data associated with this study will be provided by the corresponding author upon request.
Bibliography
- Archibald, J. (1998). Second language phonology, phonetics, and typology. Studies in Second Language Acquisition, 20(2), 189–211. https://doi.org/10.1017/S0272263198002046
- Baumgardner, R. J. (1995). Pakistani English: Acceptability and the norm. World Englishes, 14(2), 261–271. https://doi.org/10.1111/j.1467-971X.1995.tb00355.x
- Beddor, P. S. (1993). The perception of nasal vowels. In M. K. Huffman & R. A. Krakow (Eds.), Nasals, nasalization, and the velum (pp. 171–196). Academic Press.
- Bell-Berti, F. (1993). Understanding velic motor control: Studies of segmental context. In M. K. Huffman & R. A. Krakow (Eds.) Nasals, nasalization, and the velum (pp. 63–85). Academic Press.
- Chen, M. Y. (1997). Acoustic correlates of English and French nasalized vowels. The Journal of the Acoustical Society of America, 102(4), 2360–2370. https://doi.org/10.1121/1.419620
- Cagliari, L. C. (1977). An experimental study of nasality with a particular reference to Brazilian Portuguese [Doctoral dissertation, University of Edinburgh, Edinburgh]. Edinburgh Research Archive. http://hdl.handle.net/1842/17275
- Chen, N. F., Slifka, J. L., & Stevens, K. N. (2007). Vowel nasalization in American English: Acoustic variability due to phonetic context. Speech Communication, 49, 905–918.
- Fujimura, O., & Lindqvist, J. (1971). Sweep-tone measurements of vocal-tract characteristics. The Journal of the Acoustical Society of America, 49(2B), 541–558. https://doi.org/10.1121/1.1912385
- Hassan, A. (2016). Assimilation and incidental differences in Sindhi language. Eurasian Journal of Humanities, 2(1), 1–15.
- House, A. S., & Stevens, K. N. (1956). Analog studies of the nasalization of vowels. Journal of Speech and Hearing Disorders, 21(2), 218–232. https://doi.org/10.1044/jshd.2102.218
- Kluender, K. R., Diehl, R. L., & Wright, B. A. (1988). Vowel-length differences after voiced and voiceless consonants: An auditory explanation. Journal of Phonetics, 16, 153–169. https://doi.org/10.1016/S0095-4470(19)30480-2
- Kluge D. C., Reis M. S., Nobre-Oliveira D., & Rauber A. S. (2008). Intelligibility of accented speech: The perception of word-final nasals by Dutch and Brazilians [Paper presentation]. Proceedings of V Jornadas en Tecnologia del Habla, Bilbao, Spain. http://lorien.die.upm.es/~lapiz/rtth/JORNADAS/V/pdfs/articulo/art_49.pdf
- Ladefoged, P., & Disner, S. F. (2012). Vowels and consonants. John Wiley & Sons, Ltd.
- Ladefoged, P., & Maddieson, I. (2001) Vowels of the World’s Languages. In C. Kriedler (Ed.), Phonology: Critical concepts. Routledge.
- Maeda, S. (1982). A digital simulation method of the vocal-tract system. Speech Communication, 1(3-4), 199–229.
- Mahboob, A., & Ahmer, N. H. (2004). Pakistani English: Phonology. In E. W. Schneider (Ed.), A handbook of varieties of English: A multimedia reference tool (pp. 1002–1017). Mouton de Gruyter.
- Mahmood, R., Hussain, Q., & Mahmood, A. (2011). Phonological adaptations of English words borrowed into Punjabi. European Journal of Social Sciences, 22(2), 234–245.
- Major, R. C. (2008). Transfer in second language phonology. In J. G. H. Edwards & M. L. Zampini (Eds.), Phonology and second language acquisition (pp. 63–94). John Benjamins Publishing Company.
- McAllister, R., Flege, J. E., & Piske, T. (2002). The influence of L1 on the acquisition of Swedish quantity by native speakers of Spanish, English and Estonian. Journal of Phonetics, 30(2), 229–258. https://doi.org/10.1006/jpho.2002.0174
- Pruthi, T., & Espy-Wilson, C. Y. (2007). Acoustic parameters for the automatic detection of vowel nasalization [Paper presentation]. 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium.
- Rahman, T. (1990). Pakistani English: The linguistic description of a non-native variety of English. National Institute of Pakistan Studies.
- Raza, W. (2008). Patterns of Pakistani English pronunciation and pedagogic priorities. Market Forces, 4(3), 102–112.
- Rehman, I. (2019). Urdu vowel system and perception of English vowels by Punjabi-Urdu speakers (Publication No. 28130860) [Doctoral dissertation, University of Kent]. ProQuest Dissertation & Theses. https://doi.org/10.22024/UniKent/01.02.76180
- Saleem, A. M., Kabir, H., Riaz, M. K., Rafique, M. M., Khalid, N., & Shahid, S. R. (2002). Urdu consonantal and vocalic sounds. Center for Research in Urdu Language Processing. https://www.readkong.com/page/urdu-consonantal-and-vocalic-sounds-6890362
- Singh, P., & Lehal, G. S. (2010). Corpus based statistical analysis of Punjabi syllables for preparation of Punjabi speech database. International Journal of Intelligent Computing Research (IJICR), 2(1), 124–128.
- Wali, A. (2003). The rules governing the writing-pronunciation contrast in Urdu: A phonological study. Center for Research in Urdu Language Processing. https://tinyurl.com/58x5ye64
- Whalen, D. H., & Beddor, P. S. (1989). Connections between nasality and vowel duration and height: Elucidation of the Eastern Algonquian intrusive nasal. Language, 65(3), 457–486. https://doi.org/10.2307/415219
- Zahid, S., & Hussain, S. (2012). An acoustic study of vowel nasalization in Punjabi [Paper presentation]. 4th International Conference of Language and Technology (CLT12), Lahore, Pakistan.
- Zhanming, W. (2014). Review of the influence of L1 in L2 acquisition. Studies in Literature and Language, 9(2), 57–60. https://doi.org/10.3968/5721
- Zobl, H. (1980). The formal and developmental selectivity of LI influence on L2 acquisition. Language Learning, 30(1), 43–57. https://doi.org/10.1111/j.1467-1770.1980.tb00150.x